PL/SQL过程语言参考
1.概述
PL/SQL是一种用于UXDB数据库系统的可载入的过程语言。PL/SQL的设计目标是创建一种这样的可载入过程语言。
-
可以被用来创建函数和触发器过程
-
对SQL语言增加控制结构
-
可以执行复杂计算
-
继承所有用户定义类型、函数和操作符
-
可以被定义为受服务器信任
-
便于使用
用PL/SQL创建的函数可以被用在任何可以使用内建函数的地方。例如,可以创建复杂条件的计算函数并且后面用它们来定义操作符或把它们用于索引表达式。
PL/SQL是默认被安装的。但是它仍然是一种可载入模块,因此特别关注安全性的管理员可以选择移除它。
1.1.使用 PL/SQL 的优点
SQL被UXDB和大多数其他关系数据库用作查询语言。它是可移植的并且容易学习。但是每一个SQL语句必须由数据库服务器单独执行。
这说明客户端应用必须发送每一个查询到数据库服务器、等待它被处理、接收并处理结果、做一些计算,然后发送更多查询给服务器。如果客户端和数据库服务器不在同一台机器上,所有这些会引起进程间通信并且将带来网络负担。
通过PL/SQL,可以将一整块计算和一系列查询分组在数据库服务器内部,这样就有了一种过程语言的能力并且使 SQL 更易用,但是节省了相当多的客户端/服务器通信开销。
-
客户端和服务器之间的额外往返通信被消除
-
客户端不需要的中间结果不必被整理或者在服务器和客户端之间传送
-
多轮的查询解析可以被避免
与不使用存储函数的应用相比,这能够导致可观的性能提升。
还有,通过PL/SQL可以使用 SQL 中所有的数据类型、操作符和函数。
1.2.支持的参数和结果数据类型
PL/SQL编写的函数可以接受服务器支持的任何标量或数组数据类型作为参数,并且它们能够返回任何这些类型的结果。它们也能接受或返回任何用名称指定的组合类型(行类型)。还可以声明一个PL/SQL函数为接受record,这表示任意组合类型都将作为输入,或者声明为返回record,表示结果是一种行类型,它的列由调用查询中的说明确定。
PL/SQL函数可以通过使用VARIADIC标记被声明为接受数量不定的参数。
PL/SQL函数也可以被声明为接受并返回多态类型anyelement、anyarray、anynonarray、anyenum以及anyrange。由一个多态函数处理的实际数据类型会随着调用改变。在声明函数参数中展示了一个示例。
PL/SQL函数还能够被声明为返回一个任意(可作为一个单一实例返回的)数据类型的“集合”(或表)。这样的一个函数通过为结果集的每个期望元素执行RETURN NEXT来产生输出,或者通过使用RETURN QUERY来输出一个查询计算的结果。
最后,如果一个PL/SQL函数没有可用的返回值,它可以被声明为返回void(另外一种选择是,在那种情况下它可以被写作一个过程)。
PL/SQL函数也能够被声明为用输出参数代替返回类型的一个显式说明。这没有为该语言增加任何基础功能,但是它常常很方便,特别是对于要返回多个值的情况。RETURNS TABLE符号也可以被用来替代RETURNS SETOF。
2.PL/SQL的结构
通过执行CREATE FUNCTION命令,以PL/SQL写成的函数可以被定义到服务器中。这种命令一般如下所示:
CREATE FUNCTION somefunc(integer, text) RETURNS integer
AS 'function body text'
LANGUAGE plsql;
就目前CREATE FUNCTION所关心的来说,函数体就是简单的一个字符串。通常在写函数体时,使用美元符号引用通常比使用普通单引号语法更有帮助。如果没有美元引用,函数体中的任何单引号或者反斜线必须通过双写来转义。这一章中几乎所有的示例都在其函数体中使用美元符号引用。
PL/SQL是一种块结构的语言。一个函数体的完整文本必须是一个块。一个块的定义如下所示。
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END [ label ];
在一个块中的每一个声明和每一个语句都由一个分号终止。如上所示,出现在另一个块中的块必须有一个分号在END之后。不过最后一个结束函数体的END不需要一个分号。
提示
一种常见的错误是直接在BEGIN之后写一个分号。这是不正确的并且将会导致一个语法错误。
如果想要标识一个块以便在一个EXIT语句中使用或者标识在该块中声明的变量名,那么label是唯一需要的。如果一个标签在END之后被给定,它必须匹配在块开始处的标签。
所有的关键词都是大小写无关的。除非被双引号引用,标识符会被隐式地转换为小写形式,就像它们在普通SQL命令中。
PL/SQL代码中的注释和普通 SQL 中的一样。一个双连字符(--)开始一段注释,它延伸到该行的末尾。一个/* 开始一段块注释,它会延伸到匹配 */ 出现的位置。块注释可以嵌套。 一个块的语句节中的任何语句可以是一个子块。子块可以被用来逻辑分组或者将变量局部化为语句的一个小组。在子块的持续期间,在一个子块中声明的变量会掩盖外层块中相同名称的变量。但是如果用块的标签限定外层变量的名字,仍然可以访问它们。如下所示。
CREATE FUNCTION somefunc() RETURNS integer AS $$
<< outerblock >>
DECLARE
quantity integer := 30;
BEGIN
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 30
quantity := 50;
--
-- 创建一个子块
--
DECLARE
quantity integer := 80;
BEGIN
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 80
RAISE NOTICE 'Outer quantity here is %', outerblock.quantity; -- Prints 50
END;
RAISE NOTICE 'Quantity here is %', quantity; -- Prints 50
RETURN quantity;
END;
$$ LANGUAGE plsql;
注意
在任何PL/SQL函数体的外部确实有一个隐藏的“外层块”包围着。这个块提供了该函数参数(如果有)的声明,以及某些诸如FOUND之类特殊变量(见获得结果状态)。外层块被标上函数的名称,这意味着参数和特殊变量可以用该函数的名称限定。
重要的是不要把PL/SQL中用来分组语句的BEGIN/END与用于事务控制的同名 SQL 命令弄混。PL/SQL的BEGIN/END只用于分组,它们不会开始或结束一个事务。有关PL/SQL中管理事务的信息,请参见事务管理。此外,一个包含EXCEPTION子句的块实际上会形成一个子事务,它可以被回滚而不影响外层事务。详见俘获错误。
3.声明
在一个块中使用的所有变量必须在该块的声明小节中声明(唯一的例外是在一个整数范围上迭代的FOR循环变量会被自动声明为一个整数变量,并且相似地在一个游标结果上迭代的FOR循环变量会被自动地声明为一个记录变量)。
PL/SQL变量可以是任意 SQL 数据类型,例如integer、varchar和char。
这里是变量声明的一些示例,如下所示。
user_id integer;
quantity numeric(5);
url varchar;
myrow tablename%ROWTYPE;
myfield tablename.columnname%TYPE;
arow RECORD;
一个变量声明的一般语法,如下所示。
name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
如果给定DEFAULT子句,它会指定进入该块时分配给该变量的初始值。如果没有给出DEFAULT子句,则该变量被初始化为SQL空值。CONSTANT选项阻止该变量在初始化之后被赋值,这样它的值在块的持续期内保持不变。COLLATE选项指定用于该变量的一个排序规则(见PL/SQL变量的排序规则)。如果指定了NOT NULL,对该变量赋值为空值会导致一个运行时错误。所有被声明为NOT NULL的变量必须被指定一个非空默认值。等号(=)可以被用来代替 PL/SQL-兼容的:=。
一个变量的默认值会在每次进入该块时被计算并且赋值给该变量(不是每次函数调用只计算一次)。因此,例如将now()赋值给类型为timestamp的一个变量将会导致该变量具有当前函数调用的时间,而不是该函数被预编译的时间。
示例:
quantity integer DEFAULT 32;
url varchar := 'http://mysite.com';
user_id CONSTANT integer := 10;
3.1.声明函数参数
传递给函数的参数被命名为标识符$1、$2等等。可选地,能够为$n参数名声明别名来增加可读性。不管是别名还是数字标识符都能用来引用参数值。
有两种方式来创建一个别名。比较好的方式是在CREATE FUNCTION命令中为参数给定一个名称。如下所示。
CREATE FUNCTION sales_tax(subtotal real) RETURNS real AS $$
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plsql;
另一种方式是显式地使用声明语法声明一个别名。
name ALIAS FOR $n;
使用这种风格的同一个示例,如下所示。
CREATE FUNCTION sales_tax(real) RETURNS real AS $$
DECLARE
subtotal ALIAS FOR $1;
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plsql;
注意
这两个示例并非完全等效。在第一种情况中,subtotal可以被引用为sales_tax.subtotal,但在第二种情况中它不能这样引用(如果为内层块附加了一个标签,subtotal则可以用那个标签限定)。
更多示例:
CREATE FUNCTION instr(varchar, integer) RETURNS integer AS $$
DECLARE
v_string ALIAS FOR $1;
index ALIAS FOR $2;
BEGIN
-- 这里是一些使用 v_string 和 index 的计算
END;
$$ LANGUAGE plsql;
CREATE FUNCTION concat_selected_fields(in_t sometablename) RETURNS text AS $$
BEGIN
RETURN in_t.f1 || in_t.f3 || in_t.f5 || in_t.f7;
END;
$$ LANGUAGE plsql;
当一个PL/SQL函数被声明为带有输出参数,输出参数可以用普通输入参数相同的方式被给定$n名称以及可选的别名。输出参数包括OUT和INOUT参数,一个OUT参数实际上是一个最初为NULL的变量,一个INOUT参数的初始值像IN参数一样是入参的值。与IN参数不同的是,OUT参数和INOUT参数的最终值在函数执行结束阶段会写入实际参数对应的变量。例如,sales-tax也可以使用如下方式。
CREATE FUNCTION sales_tax(subtotal real, OUT tax real) RETURNS VOID AS $$
BEGIN
tax := subtotal * 0.06;
END;
$$ LANGUAGE plsql;
在一个匿名块中调用:
DO
$$
DECLARE
amount real;
BEGIN
amount=0;
perform sales_tax(100, amount);
RAISE NOTICE 'amount:%', amount;
END;
$$
LANGUAGE PLSQL;
变量amount的值在函数sales_tax执行后被修改为6。注意带有输出参数的PLSQL函数也只能被PLSQL语言调用。
声明一个PL/SQL函数的另一种方式是用RETURNS TABLE,如下所示。
CREATE FUNCTION extended_sales(p_itemno int)
RETURNS TABLE(quantity int, total numeric) AS $$
BEGIN
RETURN QUERY SELECT s.quantity, s.quantity * s.price FROM sales AS s
WHERE s.itemno = p_itemno;
END;
$$ LANGUAGE plsql;
这和声明一个或多个OUT参数并且指定RETURNS SETOF sometype完全等效。
当一个PL/SQL函数的返回类型被声明为一个多态类型(anyelement、anyarray、anynonarray、anyenum或anyrange),一个特殊参数$0会被创建。它的数据类型是该函数的实际返回类型,这是从实际输入类型推演得来。$0被初始化为空并且不能被该函数修改,因此它能够被用来保持可能需要的返回值,不过这不是必须的。$0也可以被给定一个别名。例如,这个函数工作在任何具有一个+操作符的数据类型上:
CREATE FUNCTION add_three_values(v1 anyelement, v2 anyelement, v3 anyelement)
RETURNS anyelement AS $$
DECLARE
result ALIAS FOR $0;
BEGIN
result := v1 + v2 + v3;
RETURN result;
END;
$$ LANGUAGE plsql;
3.2.ALIAS
newname ALIAS FOR oldname;
ALIAS语法比前一节中建议的更一般化:可以为任意变量声明一个别名,而不只是函数参数。其主要实际用途是为预先决定了名称的变量分配一个不同的名称,例如在一个触发器过程中的NEW或OLD。
示例:
DECLARE
prior ALIAS FOR old;
updated ALIAS FOR new;
因为ALIAS创造了两种不同的方式来命名相同的对象,如果对其使用不加限制就会导致混淆。最好只把它用来覆盖预先决定的名称。
3.3.数据类型
每个PL/SQL常量、变量、参数和函数返回值都有一个数据类型,它决定了它的存储格式以及它的有效值和操作。
本节解释了标量数据类型,它存储没有内部组件的值。
标量数据类型可以有子类型。子类型是一种数据类型,它是另一种数据类型的子集,另一种数据类型是它的基本类型。子类型具有与其基类型相同的有效操作。数据类型及其子类型构成数据类型簇。
PL/SQL预定义了许多类型和子类型,并允许您定义自己的子类型。
3.3.1.SQL数据类型
PL/SQL数据类型包括SQL数据类型。
-
新增的
BINARY_FLOAT和BINARY_DOUBLE的PL/SQL子类型与SQL不同,PL/SQL允许声明以下类型的变量: -
CHAR和VARCHAR2变量
3.3.1.1.BINARY_FLOAT和BINARY_DOUBLE的其他PL/SQL子类型
PL/SQL 预定义了这些子类型。
| 类型名 | 基类型 | SQL 支持? | NULL 约束 | 数据范围 |
|---|---|---|---|---|
BINARY_FLOAT | NUMBER | 否 | 小数点前最高 131,072 位,小数点后最高 16,383 位 | |
BINARY_DOUBLE | NUMBER | 否 | 小数点前最高 131,072 位,小数点后最高 16,383 位 | |
SIMPLE_FLOAT | BINARY_FLOAT | 否 | NOT NULL | 小数点前最高 131,072 位,小数点后最高 16,383 位 |
SIMPLE_DOUBLE | BINARY_DOUBLE | 否 | NOT NULL | 小数点前最高 131,072 位,小数点后最高 16,383 位 |
3.3.1.2.CHAR和VARCHAR2变量
PLSQL中CHAR和VARCHAR2的表现和SQL层保持一致。
3.3.1.2.1.预定义类型
在PLSQL中CHARACTER作为CHAR子类型,特性和CHAR保持一致。
在PLSQL中STRING作为VARCHAR2子类型,特性和VARCHAR2保持一致。
| 类型名 | 基类型 | SQL 支持? | NULL? |
|---|---|---|---|
char | — | 是 | Yes |
character | char | 是 | Yes |
varchar2 | — | 是 | Yes |
varchar | varchar2 | 是 | Yes |
string | varchar2 | 否 | Yes |
3.3.2.布尔数据类型
PL/SQL数据类型BOOLEAN存储逻辑值,即布尔值TRUE和FALSE以及NULL值。NULL表示未知值。和SQL中的BOOLEAN保持一致。
3.3.3.PLS_INTEGER和BINARY_INTEGER数据类型
PL/SQL数据类型PLS_INTEGER和BINARY_INTEGER是相同的。
为简单起见,本文使用PLS_INTEGER来表示PLS_INTEGER和BINARY_INTEGER。
PLS_INTEGER数据类型存储-2,147,483,648到2,147,483,647范围内的带符号整数,以32位表示。
| 类型名 | 基类型 | SQL 支持? | NULL? | 数据范围 |
|---|---|---|---|---|
BINARY_INTEGER | INTEGER | 否 | Yes | $-2,147,483,648$ 到 $2,147,483,647$ |
PLS_INTEGER | BINARY_INTEGER | 否 | Yes | $-2,147,483,648$ 到 $2,147,483,647$ |
3.3.3.1.预定义的PLS_INTEGER子类型
| 类型名 | 基类型 | 说明 | SQL 支持 | NULL 约束 | 数据范围 |
|---|---|---|---|---|---|
NATURAL | BINARY_INTEGER | PLS_INTEGER 的非负值 | 否 | $0$ 到 $2,147,483,647$ | |
NATURALN | NATURAL | 带 NOT NULL 约束的非负值 | 否 | NOT | $0$ 到 $2,147,483,647$ |
POSITIVE | BINARY_INTEGER | PLS_INTEGER 的正值 | 否 | $1$ 到 $2,147,483,647$ | |
POSITIVEN | POSITIVE | 带 NOT NULL 约束的正值 | 否 | NOT | $1$ 到 $2,147,483,647$ |
SIGNTYPE | BINARY_INTEGER | 三态逻辑值($-1$、$0$ 或 $1$) | 否 | $-1$ 到 $1$ | |
SIMPLE_INTEGER | BINARY_INTEGER | 带 NOT NULL 约束的 PLS_INTEGER | 否 | NOT | $-2,147,483,648$ 到 $2,147,483,647$ |
3.3.3.2.PLS_INTEGER 的 SIMPLE_INTEGER 子类型
SIMPLE_INTEGER是PLS_INTEGER数据类型的预定义子类型。
SIMPLE_INTEGER与PLS_INTEGER具有相同的范围并具有NOT NULL约束。
| 类型名 | Ora 基类型 | SQL 支持? | NULL 约束 | 数据范围 |
|---|---|---|---|---|
SIMPLE_INTEGER | BINARY_INTEGER | 否 | NOT NULL | -2,147,483,648 到 2,147,483,647 |
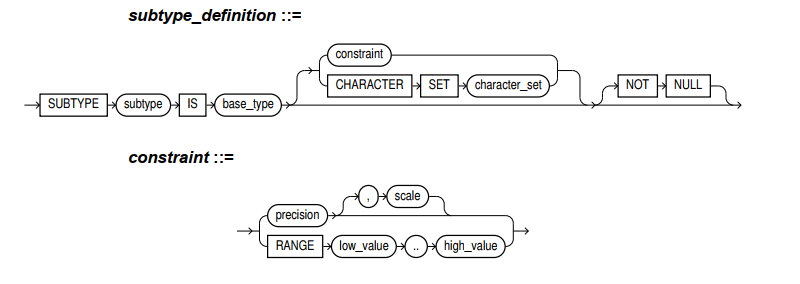
3.3.4.用户定义的 PL/SQL 子类型
用户自定义子类型分为两种带约束和不带约束。
不受约束的子类型与其基类型具有相同的值集,因此它只是基类型的另一个名称。
DECLARE
SUBTYPE num1 is numeric(2,1) not null;
BEGIN
null;
end;
/
DECLARE
SUBTYPE num2 is PLS_INTEGER RANGE 1 .. 100 not null;
BEGIN
null;
end;
/
3.4.复制类型
variable%TYPE
%TYPE提供了一个变量或表列的数据类型。可以用它来声明将保持数据库值的变量。例如,如果在users中有一个名为user_id的列。要定义一个与users.user_id具有相同数据类型的变量,如下所示。
user_id users.user_id%TYPE;
通过使用%TYPE,不需要知道要引用的结构的实际数据类型,而且最重要地,如果被引用项的数据类型在未来被改变(例如把user_id的类型从integer改为real),不需要改变函数定义。
%TYPE在多态函数中特别有价值,因为内部变量所需的数据类型能在两次调用时改变。可以把%TYPE应用在函数的参数或结果占位符上来创建合适的变量。
3.5.行类型
name table_name%ROWTYPE;
name composite_type_name;
一个组合类型的变量被称为一个行变量(或行类型变量)。这样一个变量可以保持一个SELECT或FOR查询结果的一整行,前提是查询的列集合匹配该变量被声明的类型。该行值的各个域可以使用通常的点号标记访问,例如rowvar.field。
通过使用table_name%ROWTYPE标记,一个行变量可以被声明为具有和一个现有表或视图的行相同的类型。它也可以通过给定一个组合类型名称来声明(因为每一个表都有一个相关联的具有相同名称的组合类型,所以在UXDB中实际上写不写%ROWTYPE都没有关系。但是带有%ROWTYPE的形式可移植性更好)。
一个函数的参数可以是组合类型(完整的表行)。在这种情况下,相应的标识符$n将是一个行变量,并且可以从中选择域,例如$1.user_id。
这里是一个使用组合类型的示例。table1和table2是已有的表,它们至少有以下提到的域,如下所示。
CREATE FUNCTION merge_fields(t_row table1) RETURNS text AS $$
DECLARE
t2_row table2%ROWTYPE;
BEGIN
SELECT * INTO t2_row FROM table2 WHERE ... ;
RETURN t_row.f1 || t2_row.f3 || t_row.f5 || t2_row.f7;
END;
$$ LANGUAGE plsql;
SELECT merge_fields(t.*) FROM table1 t WHERE ... ;
3.6.记录类型
记录类型的变量,其整体或部分(用取成员操作符‘.’)可以赋值,并可用于任意表达式中。
3.6.1.本地记录类型
在 plsql 的语句块的声明端中可以定义本地记录类型,之后此记录类型在本语句块的作用范围内可用以定义变量。
本地记录类型定义语法:
record_type_definition ::= : TYPE typname IS RECORD '(' record_type_fields ')' ';'
record_type_fields ::= field_definition [ (',' field_definition) ... ]
field_definition ::= fieldname datatype [ NOT NULL [ ':=' | DEFAULT ] expression ]
3.6.2.系统组合类型
利用SQL语句
CREATE TYPE name AS ( [ attribute_name data_type [ COLLATE collation ] [, ... ] ] )
或
CREATE TABLE name AS ( [ attribute_name data_type [ COLLATE collation ] [, ... ] ] )
创建的系统组合类型。
3.6.3.虚拟记录类型
RECORD 为系统虚拟记录类型,用以在过程式语言中定义编程时不确定结构的记录变量。此类型变量可以被赋予任意一种本地记录类型或系统组合类型的值,此变量的实际类型由最近一次的赋值决定。虚拟记录类型变量第一次赋值之前,为不定值 NULL。
3.7.集合类型
PL/UXSQL中有三种集合类型:关联数组(associative array)、可变数组(VARRAY)和嵌套表(nested table)。
3.7.1.关联数组类型
-
语法
TYPE table_type IS TABLE OF data_type [NOT NULL] INDEX BY index_type -
参数
-
table_type要定义的类型名。
-
data_type要创建的集合中成员的类型。
-
index_type创建集合索引的类型。
-
NOT NULL要创建的集合中成员不能为
NULL。
-
-
说明
-
在插入值时,变量会自动增长,访问越界会放回一个
NULL,不会报错。 -
在存储过程中定义的类型,其作用域仅在该存储过程中。
-
索引的类型仅支持
INTEGER和VARCHAR类型,其中VARCHAR的长度暂不约束。 -
data_type可以是基础类型或用户自定义类型,不可以为数组类型。 -
不支持该类型的变量作为函数的出入参。
-
不支持通过
RAISE NOTICE打印整个嵌套变量。 -
不支持下标使用
NULL给元素赋值。
-
3.7.2.可变数组类型
-
语法
TYPE varray_type IS {VARRAY | VARYING ARRAY}(size) OF data_type [NOT NULL] -
参数
-
varray_type要定义的类型名。
-
size取值为正整数,表示可以容纳的成员的最大数量。
-
data_type要创建的集合中成员的类型。
-
NOT NULL要创建的集合中成员不能为
NULL。
-
-
说明
-
在插入值时,变量会自动增长,访问越界会放回一个
NULL,不会报错。 -
在存储过程中定义的类型,其作用域仅在该存储过程中。
-
data_type可以是基础类型或用户自定义类型,不可以为数组类型、嵌套表类型和关联数组类型。 -
data_type可以是基础类型或用户自定义类型,不可以为数组类型。 -
不支持该类型的变量作为函数的出入参。
-
size仅语法支持,暂未支持功能。 -
不支持下标使用
NULL给元素赋值。
-
3.7.3.嵌套表类型
-
语法
TYPE table_type IS TABLE OF data_type [NOT NULL] -
参数
-
table_type要定义的类型名。
-
data_type要创建的集合中成员的类型。
-
NOT NULL要创建的集合中成员不能为
NULL。
-
-
说明
-
在插入值时,变量会自动增长,访问越界会放回一个
NULL,不会报错。 -
在存储过程中定义的类型,其作用域仅在该存储过程中。
-
data_type可以是基础类型或用户自定义类型,不可以为数组类型。 -
不支持该类型的变量作为函数的出入参。
-
不支持通过
RAISE NOTICE打印整个嵌套变量。 -
不支持下标使用
NULL给元素赋值。
-
3.7.4.使用方法
通过集合构造函数和集合变量赋值给变量初始化和赋值,然后使用集合方法进行调用。说明如下所示。
-
集合构造函数
集合构造函数是与集合类型同名的系统定义函数,它返回该类型的集合。
构造函数调用的语法如下所示。
collection_type ( [ value [, value ]... ] )如果参数列表为空,构造函数返回一个空集合;否则,构造函数返回一个包含指定值的集合。可以在变量声明和块的可执行部分中将返回的集合分配给集合变量。
-
集合变量赋值
可以通过如下方式为集合变量赋值。
-
调用构造函数创建集合并将其分配给集合变量(关联数组类型变量不支持)。
-
使用赋值语句将另一个现有集合变量的值赋给它。
-
要为集合变量的元素赋值,需要将该元素引用为collection_variable_name(index)并为其赋值,赋值方法如下所示。
-
使用赋值语句直接赋值或将另一个现有集合变量中的元素的值赋给它。
-
使用
INTO语句赋值。 -
集合方法
集合方法调用的基本语法如下所示。
collection_name.methodmethod选项
语法 描述 DELETE删除元素: 1. DELETE/DELETE():删除集合中的所有元素。 2.DELETE(n):删除索引为n的元素。若不存在则不执行动作。注意:删除后,索引在n之后的元素会全部前移一位。TRIM末尾删除(不支持 VARCHAR索引的关联数组): 1.TRIM/TRIM():从末尾删除一个元素。集合为空时不执行动作。 2.TRIM(n):从末尾删除n个元素。若集合不足n个元素,则清空集合。EXTEND末尾添加(不支持 VARCHAR索引的关联数组): 1.EXTEND/EXTEND():向集合末尾添加一个NULL元素。 2.EXTEND(n):向集合末尾添加n个NULL元素。EXISTS存在性检查: 1. 可变数组/嵌套表:若第 n个元素存在则返回TRUE,否则返回FALSE。 2. 关联数组:若索引为n的元素存在则返回TRUE,否则返回FALSE。 3. 若n超过当前元素总数,统一返回FALSE。FIRST和LAST边界索引获取: 1. 集合为空返回 NULL;仅一个元素时两者相同。 2. 关联数组:索引为INTEGER时返回最小/最大索引;索引为VARCHAR时返回排序后最低/最高索引。 3. 可变数组/嵌套表:FIRST恒为 1,LAST恒等于COUNT。COUNT计数:返回集合中当前元素的总个数。 PRIOR和NEXT集合遍历: 1. PRIOR(n):返回索引n的前一个索引,不存在则返回NULL。 2.NEXT(n):返回索引n的后一个索引,不存在则返回NULL。 3. 边界情况:c.PRIOR(c.FIRST)和c.NEXT(c.LAST)均返回NULL。 -
示例
DECLARE -- 定义一个元素类型为NUMERIC,索引类型为VARCHAR的关联数组类型 TYPE population IS TABLE OF NUMERIC INDEX BY VARCHAR(64); -- 定义关联数组变量 city_population population; i VARCHAR(64); BEGIN -- 通过指定下标给变量赋值 city_population('Smallville') := 2000; city_population('Midland') := 750000; city_population('Megalopolis') := 1000000; city_population('Smallville') := 2001; -- 通过FIRST和NEXT方法遍历整个变量 i := city_population.FIRST; WHILE i IS NOT NULL LOOP RAISE NOTICE 'Population of % is %', i, city_population(i); i := city_population.NEXT(i); END LOOP; END; /
3.8.PL/SQL变量的排序规则
当一个PL/SQL函数有一个或多个可排序数据类型的参数时,为每一次函数调用都会基于赋值给实参的排序规则来确定出一个排序规则。如果一个排序规则被成功地确定(即在参数之间隐式排序规则没有冲突),那么所有的可排序参数会被当做隐式具有那个排序规则。这将在函数中影响行为受到排序规则影响的操作。例如,考虑less_than的第一次使用将会采用text_field_1和text_field_2共同的排序规则进行比较,而第二次使用将采用C排序规则。如下所示。
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b;
END;
$$ LANGUAGE plsql;
SELECT less_than(text_field_1, text_field_2) FROM table1;
SELECT less_than(text_field_1, text_field_2 COLLATE "C") FROM table1;
此外,被确定的排序规则也被假定为任何可排序数据类型本地变量的排序规则。因此,当这个函数被写为以下形式时,它工作将不会有什么不同。
CREATE FUNCTION less_than(a text, b text) RETURNS boolean AS $$
DECLARE
local_a text := a;
local_b text := b;
BEGIN
RETURN local_a < local_b;
END;
$$ LANGUAGE plsql;
如果没有可排序数据类型的参数,或者不能为它们确定共同的排序规则,那么参数和本地变量会使用它们数据类型的默认排序规则(通常是数据库的默认排序规则,但是可能不同于域类型的变量)。
通过在一个可排序数据类型的本地变量的声明中包括COLLATE选项,可以为它指定一个不同的排序规则,如下所示。
DECLARE
local_a text COLLATE "en_US";
这个选项会覆盖根据上述规则被给予该变量的排序规则。
还有,如果一个函数想要强制在一个特定操作中使用一个特定排序规则,当然可以在该函数内部写一个显式的COLLATE子句。如下所示。
CREATE FUNCTION less_than_c(a text, b text) RETURNS boolean AS $$
BEGIN
RETURN a < b COLLATE "C";
END;
$$ LANGUAGE plsql;
这会覆盖表达式中使用的表列、参数或本地变量相关的排序规则,就像在纯SQL命令中发生的一样。
3.9.子函数/过程声明
在plsql语句块声明段中声明无参数的子函数/过程时,不可带空括号。
3.9.1.子函数头
-
语法
FUNCTION function_name RETURN datatype ; FUNCTION function_name ( parameter_declaration (,parameter_declaration )*) RETURN datatype ; -
示例
create function f01 RETURN int as num int :=2; function f2 return integer is var1 int default 1; function f1(num int) return integer is var1 int default 2; begin raise notice 'f1--var1无前缀:%',var1; raise notice 'f1--var1有前缀f1:%',f1.var1; raise notice 'f1--var1有前缀f1:外f2.var1:%',f2.var1; return 0; end; begin raise notice 'aaa:%',f1(num); return f1(num); end; begin perform f2; return 1; end; /
3.9.2.子过程头
-
语法
PROCEDURE procedure_name; PROCEDURE procedure_name (parameter_declaration (, parameter_declaration )* );
4.表达式
PL/SQL语句中用到的所有表达式会被服务器的主SQL执行器处理。例如,当写一个这样的PL/SQL语句时
IF expression THEN ...
PL/SQL将通过给主 SQL 引擎发送一个查询来计算该表达式,如下所示。
SELECT expression
如变量替换中所详细讨论的,在构造该SELECT命令时,PL/SQL变量名的每一次出现会被参数所替换。这允许SELECT的查询计划仅被准备一次并且被重用于之后的对于该变量不同值的计算。因此,在一个表达式第一次被使用时实际发生的本质上是一个PREPARE命令。例如,如果已经声明了两个整数变量x和y,并且写了
IF x < y THEN ...
在现象之后发生的等效于
PREPARE statement_name(integer, integer) AS SELECT $1 < $2;
并且然后为每一次IF语句的执行,这个预备语句都会被EXECUTE,执行时使用变量的当前值作为参数值。通常这些细节对于一个PL/SQL用户并不重要,但是在尝试诊断一个问题时了解它们很有用。更多信息可见计划缓存。
5.基本语句
在这一节和接下来的小节中,会描述PL/SQL能明确理解的所有语句类型。任何不被识别为这些语句类型之一的被假定为是一个SQL命令,并且会被发送给主数据库引擎执行,具体如执行一个没有结果的命令和执行一个有单一行结果的查询中所述。
5.1.赋值
为一个PL/SQL变量赋一个值,如下所示。
variable { := | = } expression;
正如以前所解释的,这样一个语句中的表达式被以一个SQL SELECT命令被发送到主数据库引擎的方式计算。该表达式必须得到一个单一值(如果该变量是一个行或记录变量,它可能是一个行值)。该目标变量可以是一个简单变量(可以选择用一个块名限定)、一个行或记录变量的域或是一个简单变量或域的数组元素。等号(=)可以被用来代替 PL/SQL-兼容的 :=。
如果该表达式的结果数据类型不匹配变量的数据类型,该值将被强制为变量的类型,就好像做了赋值造型一样。如果没有用于所涉及到的数据类型的赋值造型可用,PL/SQL解释器将尝试以文本的方式转换结果值,也就是在应用结果类型的输出函数之后再应用变量类型的输入函数。注意如果结果值的字符串形式无法被输入函数所接受,这可能会导致由输入函数产生的运行时错误。
示例
tax := subtotal * 0.06;
my_record.user_id := 20;
5.2.执行一个没有结果的命令
对于任何不返回行的SQL命令(例如没有一个RETURNING子句的INSERT),可以通过把该命令直接写在一个 PL/SQL 函数中执行它。
任何出现在该命令文本中的PL/SQL变量名被当作一个参数,并且接着该变量的当前值被提供为运行时该参数的值。这与早前描述的对表达式的处理完全相似,详见变量替换。
当以这种方式执行一个SQL命令时,如计划缓存中讨论的,PL/SQL会为该命令缓存并重用执行计划。
有时候计算一个表达式或SELECT查询但抛弃其结果是有用的,例如调用一个有副作用但是没有有用的结果值的函数。在PL/SQL中要这样做,可使用PERFORM语句,如下所示。
PERFORM query;
这会执行query并且丢弃掉结果。以写一个SQL SELECT命令相同的方式写该query,并且将初始的关键词SELECT替换为PERFORM。对于WITH查询,使用PERFORM并且接着把该查询放在圆括号中(在这种情况中,该查询只能返回一行)。PL/SQL变量将被替换到该查询中,正像对不返回结果的命令所作的那样,并且计划被以相同的方式被缓存。还有,如果该查询产生至少一行,特殊变量FOUND会被设置为真,而如果它不产生行则设置为假(见获得结果状态)。
注意
可能期望直接写SELECT能实现这个结果,但是当前唯一被接受的方式是PERFORM。一个能返回行的SQL命令(例如SELECT)将被当成一个错误拒绝,除非它像下一节中讨论的有一个INTO子句。
示例
PERFORM create_mv('cs_session_page_requests_mv', my_query);
5.3.执行一个有单一行结果的查询
一个产生单一行(可能有多个列)的SQL命令的结果可以被赋值给一个记录变量、行类型变量或标量变量列表。这通过书写基础SQL命令并增加一个INTO子句来达成。如下所示。
SELECT select_expressions INTO target FROM ...;
INSERT ... RETURNING expressions INTO target;
UPDATE ... RETURNING expressions INTO target;
DELETE ... RETURNING expressions INTO target;
其中target可以是一个记录变量、一个行变量或一个有逗号分隔的简单变量和记录/行域列表。PL/SQL变量将被替换到该查询的剩余部分中,并且计划会被缓存,正如之前描述的对不返回行的命令所做的。这对SELECT、带有RETURNING的INSERT/UPDATE/DELETE以及返回行集结果的工具命令(例如EXPLAIN)。除了INTO子句,SQL 命令和它在PL/SQL之外的写法一样。
提示
注意带INTO的SELECT的这种解释和UXDB常规的SELECT INTO命令有很大的不同,后者的INTO目标是一个新创建的表。如果想要在一个PL/SQL函数中从一个SELECT的结果创建一个表,请使用语法CREATE TABLE ... AS SELECT。
如果一行或一个变量列表被用作目标,该查询的结果列必须完全匹配该结果的结构,包括数量和数据类型,否则会发生一个运行时错误。当一个记录变量是目标时,它会自动地把自身配置成查询结果列组成的行类型。
INTO子句几乎可以出现在 SQL 命令中的任何位置。通常它被写成刚好在SELECT命令中的select_expressions列表之前或之后,或者在其他命令类型的命令最后。推荐遵循这种惯例,以防PL/SQL的解析器在未来的版本中变得更严格。
该查询必须刚好返回一行或者将会报告一个运行时错误,该错误可能是NO_DATA_FOUND(没有行)或TOO_MANY_ROWS(多于一行)。如果希望捕捉该错误,可以使用一个异常块,如下所示。
BEGIN
SELECT * INTO STRICT myrec FROM emp WHERE empname = myname;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RAISE EXCEPTION 'employee % not found', myname;
WHEN TOO_MANY_ROWS THEN
RAISE EXCEPTION 'employee % not unique', myname;
END;
对于带有RETURNING的INSERT/UPDATE/DELETE,PL/SQL也会针对多于一个返回行的情况报告一个错误。
如果为该函数启用了If print_strict_params,那么当抛出一个错误时,该错误消息的DETAIL将包括传递给该查询的参数信息。可以通过设置plsql.print_strict_params为所有函数更改print_strict_params设置,但是只有修改后被编译的函数才会生效。也可以使用一个编译器选项来为一个函数启用它,如下所示。
CREATE FUNCTION get_userid(username text) RETURNS int
AS $$
#print_strict_params on
DECLARE
userid int;
BEGIN
SELECT users.userid INTO STRICT userid
FROM users WHERE users.username = get_userid.username;
RETURN userid;
END
$$ LANGUAGE plsql;
失败时,这个函数会产生如下错误信息。
ERROR: query returned no rows
DETAIL: parameters: $1 = 'nosuchuser'
CONTEXT: PL/SQL function get_userid(text) line 6 at SQL statement
对于要处理来自于一个 SQL 查询的结果行的情况,请见通过查询结果循环。
5.4.执行动态命令
很多时候将想要在PL/SQL函数中产生动态命令,也就是每次执行中会涉及到不同表或不同数据类型的命令。PL/SQL通常对于命令所做的缓存计划尝试(如计划缓存中讨论)在这种情境下无法工作。要处理这一类问题,需要提供EXECUTE语句,如下所示。
EXECUTE [IMMEDIATE] command-string [ [ RETURNING ] [ BULK COLLECT ] INTO [STRICT] target ] [ USING expression [, ... ] ];
其中command-string是一个能得到一个包含要被执行命令字符串(类型text)的表达式。可选的target是一个记录变量、一个行变量或者一个逗号分隔的简单变量以及记录/行域的列表,该命令的结果将存储在其中。可选的USING表达式提供要被插入到该命令中的值。可以使用IN、OUT、IN OUT指定参数的使用模式。IN表示输入参数,OUT表示用于返回结果,IN OUT表示即做为输入参数又用于返回结果。未指定模式时默认为IN。OUT参数和INTO子句不能同时存在。
在计算得到的命令字符串中,不会做PL/SQL变量的替换。任何所需的变量值必须在命令字符串被构造时被插入其中,或者可以使用下面描述的参数。
还有,对于通过EXECUTE执行的命令不会有计划被缓存。该命令反而在每次运行时都会被做计划。因此,该命令字符串可以在执行不同表和列上动作的函数中被动态创建。
RETURNING子句用于PL/SQL兼容,支持在PLSQL动态语句上下文中DML语句returning子句带into。
BULK COLLECT在接收多行结果时使用,此时INTO子句中的变量必须是集合类型。
INTO子句指定一个返回行的 SQL 命令的结果应该被赋值到哪里。如果提供了一个行或变量列表,它必须完全匹配查询结果的结构(当使用一个记录变量时,它会自动把它自己配置为匹配结果结构)。如果返回多个行,只有第一个行会被赋值给INTO变量。如果没有返回行,NULL会被赋值给INTO变量。如果没有指定INTO变量,该查询结果会被抛弃。
命令字符串可以使用参数值,它们在命令中用$1、$2或:placeholder_name等格式的引用,2种格式的引用不能混用。这些符号引用在USING子句中提供的值。这种方法常常更适合于把数据值作为文本插入到命令字符串中:它避免了将该值转换为文本以及转换回来的运行时负荷,并且它更不容易被SQL注入攻击,因为不需要引用或转义。如下所示。
EXECUTE 'SELECT count(*) FROM mytable WHERE inserted_by = $1 AND inserted <= $2'
INTO c
USING checked_user, checked_date;
需要注意的是,参数符号只能用于数据值 — 如果想要使用动态决定的表名或列名,必须将它们以文本形式插入到命令字符串中。例如,如果前面的那个查询需要在一个动态选择的表上执行,如下所示。
EXECUTE 'SELECT count(*) FROM '
|| quote_ident(tabname)
|| ' WHERE inserted_by = $1 AND inserted <= $2'
INTO c
USING checked_user, checked_date;
一种更干净的方法是为表名或者列名使用format()的 %I规范(被新行分隔的字符串会被串接起来),如下所示。
EXECUTE format('SELECT count(*) FROM %I '
'WHERE inserted_by = $1 AND inserted <= $2', tabname)
INTO c
USING checked_user, checked_date;
另一个关于参数符号的限制是,它们只能在SELECT、INSERT、UPDATE和DELETE命令中工作。在另一种语句类型(通常被称为实用语句)中,即使值是数据值,也必须将它们以文本形式插入。
在上面第一个示例中,带有一个简单的常量命令字符串和一些USING参数的EXECUTE命令在功能上等效于直接用PL/SQL写的命令,并且允许自动发生PL/SQL变量替换。重要的不同之处在于,EXECUTE会在每一次执行时根据当前的参数值重新规划该命令,而PL/SQL则是创建一个通用计划并且将其缓存以便重用。在最佳计划强依赖于参数值的情况中,使用EXECUTE来明确地保证不会选择一个通用计划是很有帮助的。
EXECUTE目前不支持SELECT INTO。但是可以执行一个纯的SELECT命令并且指定INTO作为EXECUTE本身的一部分。
注意
PL/SQL中的EXECUTE语句与UXDB服务器支持的 SQL 语句无关。服务器的EXECUTE语句不能直接在PL/SQL函数中使用(并且也没有必要)。
例 在动态查询中引用值
在使用动态命令时经常不得不处理单引号的转义。推荐在函数体中使用美元符号引用来引用固定的文本(如果有使用美元符界定的老代码,请参见处理引号中的概述,这样在把上述代码转换成更合理的模式时会省力些)。
动态值需要被小心地处理,因为它们可能包含引号字符。一个使用format()的示例(这假设用美元符号引用了函数体,因此引号不需要被双写),如下所示。
EXECUTE format('UPDATE tbl SET %I = $1 '
'WHERE key = $2', colname) USING newvalue, keyvalue;
还可以直接调用引用函数:
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = '
|| quote_literal(newvalue)
|| ' WHERE key = '
|| quote_literal(keyvalue);
这个示例展示了quote_ident和quote_literal函数的使用。为了安全,在进行一个动态查询中的插入之前,包含列或表标识符的表达式应该通过quote_ident被传递。如果表达式包含在被构造出的命令中应该是字符串的值时,它应该通过quote_literal被传递。这些函数采取适当的步骤来分别返回被封闭在双引号或单引号中的文本,其中任何嵌入的特殊字符都会被正确地转义。
因为quote_literal被标记为STRICT,当用一个空参数调用时,它总是会返回空。在上面的示例中,如果newvalue或keyvalue为空,整个动态查询字符串会变成空,导致从EXECUTE得到一个错误。可以通过使用quote_nullable函数来避免这种问题,它工作起来和quote_literal相同,除了用空参数调用时会返回一个字符串NULL。如下所示。
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = '
|| quote_nullable(newvalue)
|| ' WHERE key = '
|| quote_nullable(keyvalue);
如果正在处理的参数值可能为空,那么通常应该用quote_nullable来代替quote_literal。
通常,必须小心地确保查询中的空值不会递送意料之外的结果。例如如果keyvalue为空,下面的WHERE子句永远不会成功,因为在=操作符中使用空操作数得到的结果总是为空,如下所示。
'WHERE key = ' || quote_nullable(keyvalue)
如果想让空和一个普通键值一样工作,使用用下命令。(目前,IS NOT DISTINCT FROM的处理效率不如=,因此只有在非常必要时才这样做。
'WHERE key IS NOT DISTINCT FROM ' || quote_nullable(keyvalue)
请注意美元符号引用只对引用固定文本有用。建议不要尝试如下示例。因为如果newvalue的内容碰巧含有$$,那么这段代码就会出问题。同样的缺点可能适用于选择的任何其他美元符号引用定界符。因此,要想安全地引用事先不知道的文本,必须恰当地使用quote_literal、quote_nullable或quote_ident。
EXECUTE 'UPDATE tbl SET '
|| quote_ident(colname)
|| ' = $$'
|| newvalue
|| '$$ WHERE key = '
|| quote_literal(keyvalue);
动态 SQL 语句也可以使用format函数来安全地构造。如下所示。
EXECUTE format('UPDATE tbl SET %I = %L '
'WHERE key = %L', colname, newvalue, keyvalue);
%I等效于quote_ident并且 %L等效于quote_nullable。format函数可以和USING子句一起使用,如下所示。
EXECUTE format('UPDATE tbl SET %I = $1 WHERE key = $2', colname)
USING newvalue, keyvalue;
这种形式更好,因为变量被以它们天然的数据类型格式处理,而不是无条件地把它们转换成文本并且通过%L引用它们。这也效率更高。
动态命令和EXECUTE的一个更大的示例可以在例 从PL/SQL移植一个创建另一个函数的函数到PL/SQL中找到,它会构建并且执行一个CREATE FUNCTION命令来定义一个新的函数。
5.5.获得结果状态
有好几种方法可以判断一条命令的效果。第一种方法是使用GET DIAGNOSTICS命令,其形式如下所示。
这条命令允许检索系统状态指示符。CURRENT是一个噪声词(参见得到有关一个错误的信息中的GET STACKED DIAGNOSTICS)。每个item是一个关键字, 它标识一个要被赋予给指定变量的状态值(变量应具有正确的数据类型来接收状态值)。可用的诊断项中展示了当前可用的状态项。冒号等号(:=)可以被用来取代 SQL 标准的=符号。如下所示。
GET DIAGNOSTICS integer_var = ROW_COUNT;
可用的诊断项
| 名称 | 类型 | 描述 |
|---|---|---|
ROW_COUNT | bigint | 最近执行的 SQL 命令所处理(影响)的行数。 |
UX_CONTEXT | text | 描述当前调用栈(Call Stack)的文本行,常用于错误追踪与调试。 |
第二种判断命令效果的方法是检查一个名为FOUND的boolean类型的特殊变量。在每一次PL/SQL函数调用时,FOUND开始都为假。它的值会被下面的每一种类型的语句设置。
-
如果一个
SELECT INTO语句赋值了一行,它将把FOUND设置为真,如果没有返回行则将之设置为假。 -
如果一个
PERFORM语句生成(并且抛弃)一行或多行,它将把FOUND设置为真,如果没有产生行则将之设置为假。 -
如果
UPDATE、INSERT以及DELETE语句影响了至少一行,它们会把FOUND设置为真,如果没有影响行则将之设置为假。 -
如果一个
FETCH语句返回了一行,它将把FOUND设置为真,如果没有返回行则将之设置为假。 -
如果一个
MOVE语句成功地重定位了游标,它将会把FOUND设置为真,否则设置为假。 -
如果一个
FOR或FOREACH语句迭代了一次或多次,它将会把FOUND设置为真,否则设置为假。当循环退出时,FOUND用这种方式设置;在循环执行中,尽管FOUND可能被循环体中的其他语句的执行所改变,但它不会被循环语句修改。 -
如果查询返回至少一行,
RETURN QUERY和RETURN QUERY EXECUTE语句会把FOUND设为真, 如果没有返回行则设置为假。
其他的PL/SQL语句不会改变FOUND的状态。尤其需要注意的一点是:EXECUTE会修改GET DIAGNOSTICS的输出,但不会修改FOUND的输出。
FOUND是每个PL/SQL函数的局部变量;任何对它的修改只影响当前的函数。
5.6.什么也不做
有时一个什么也不做的占位语句也很有用。例如,它能够指示if/then/else链中故意留出的空分支。可以使用NULL语句达到这个目的。
NULL;
例如,下面的两段代码是等价的。
BEGIN
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
NULL; -- 忽略错误
END;
BEGIN
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN -- 忽略错误
END;
究竟使用哪一种取决于各人的喜好。
注意
在 Oracle 的 PL/SQL 中,不允许出现空语句列表,并且因此在这种情况下必须使用NULL语句。而PL/SQL允许什么也不写。
5.7.匿名语句块
语句块由局部对象声明/定义部分和可执行部分组成,是 plsql 的基本编译单元。
语法:
plsql_block ::= [ << label >> [ ... ] ]
[ DECLARE declare_section ]
blk_body
declare_section ::= [ item_list_1 ] item_list_2
item_list_1 ::= { type_definition |
cursor_declaration |
item_declaration |
function_declaration |
procedure_declaration } [ ... ]
item_list_2 ::= { cursor_declaration |
cursor_definition |
function_declaration |
function_definition |
procedure_declaration |
procedure_definition } [ ... ]
blk_body ::= BEGIN statement ... [ EXCEPTION exception_handler ] END [ label ] ;
statement ::= [ << label >> [ ... ] ] basic_statement;
basic_statement ::= { assignment_statment |
basic_loop_statement |
assignment_statement |
basic_loop_statement |
case_statement |
close_statement |
collection_method_call |
continue_statement |
cursor_for_loop_statement |
execute_immediate_statement |
exit_statement |
fetch_statement |
for_loop_statement |
forall_statement |
goto_statement |
if_statement |
null_statement |
open_statement |
open_for_statement |
pipe_row_statement |
plsql_block |
procedure_call |
raise_statement |
return_statement |
select_into_statement |
sql_statement |
while_loop_statement }
匿名语句块也是一个可执行的语句,和其它语句一样,前面都可以有可选的多个语句标签列表, end 后的可选标签名必须存在于前面的标签列表。
5.8.BULK COLLECT子句
BULK COLLECT子句是批量SQL的一项功能,它可以将结果从SQL批量返回到PL/SQL,而不是一次一个。
BULK COLLECT子句可以出现在如下语句中。
-
SELECT INTO语句 -
FETCH语句 -
RETURNING INTO的语句:DELETE语句、INSERT语句、UPDATE语句、EXECUTE IMMEDIATE语句
使用BULK COLLECT子句,前面的每个语句都会检索整个结果集,并将其存储在单个操作中的一个或多个集合变量中(这比使用循环语句一次检索一个结果行更有效)。
6.控制结构
控制结构可能是PL/SQL中最有用的(以及最重要)的部分了。利用PL/SQL的控制结构,可以非常灵活而且强大的操纵UXDB的数据。
6.1.从一个函数返回
有两个命令可以从函数中返回数据:RETURN和RETURN NEXT。
6.1.1.RETURN
RETURN expression;
带有一个表达式的RETURN用于终止函数并把expression的值返回给调用者。这种形式被用于不返回集合的PL/SQL函数。
如果一个函数返回一个标量类型,表达式的结果将被自动转换成函数的返回类型。但是要返回一个复合(行)值,必须写一个正好产生所需列集合的表达式。这可能需要使用显式造型。
如果声明带输出参数的函数,那么就只需要写不带表达式的RETURN。输出参数变量的当前值将被返回。
如果声明函数返回void,一个RETURN语句可以被用来提前退出函数;但是不要在RETURN后面写一个表达式。
一个函数的返回值不能是未定义。如果控制到达了函数最顶层的块而没有碰到一个RETURN语句,那么会发生一个运行时错误。不过,这个限制不适用于带输出参数的函数以及返回void的函数。在这些情况中,如果顶层的块结束,将自动执行一个RETURN语句。
示例
-- 返回一个标量类型的函数
RETURN 1 + 2;
RETURN scalar_var;
-- 返回一个组合类型的函数
RETURN composite_type_var;
RETURN (1, 2, 'three'::text); -- 必须把列造型成正确的类型
6.1.2.RETURN NEXT以及RETURN QUERY
RETURN NEXT expression;
RETURN QUERY query;
RETURN QUERY EXECUTE command-string [ USING expression [, ... ] ];
当一个PL/SQL函数被声明为返回SETOF sometype,那么遵循的过程则略有不同。在这种情况下,要返回的个体项被用一个RETURN NEXT或者RETURN QUERY命令的序列指定,并且接着会用一个不带参数的最终RETURN命令来指示这个函数已经完成执行。RETURN NEXT可以被用于标量和复合数据类型;对于复合类型,将返回一个完整的结果“表”。RETURN QUERY将执行一个查询的结果追加到一个函数的结果集中。在一个单一的返回集合的函数中,RETURN NEXT和RETURN QUERY可以被随意地混合,这样它们的结果将被串接起来。
RETURN NEXT和RETURN QUERY实际上不会从函数中返回 — 它们简单地向函数的结果集中追加零或多行。然后会继续执行PL/SQL函数中的下一条语句。随着后继的RETURN NEXT和RETURN QUERY命令的执行,结果集就建立起来了。最后一个RETURN(应该没有参数)会导致控制退出该函数(或者可以让控制到达函数的结尾)。
RETURN QUERY有一种变体RETURN QUERY EXECUTE,它可以动态指定要被执行的查询。可以通过USING向计算出的查询字符串插入参数表达式,这和在EXECUTE命令中的方式相同。
如果声明函数带有输出参数,只需要写不带表达式的RETURN NEXT。在每一次执行时,输出参数变量的当前值将被保存下来用于最终返回为结果的一行。注意为了创建一个带有输出参数的集合返回函数,在有多个输出参数时,必须声明函数为返回SETOF record;或者如果只有一个类型为sometype的输出参数时,声明函数为SETOF sometype。
使用RETURN NEXT的函数,如下所示。
CREATE TABLE foo (fooid INT, foosubid INT, fooname TEXT);
INSERT INTO foo VALUES (1, 2, 'three');
INSERT INTO foo VALUES (4, 5, 'six');
CREATE OR REPLACE FUNCTION get_all_foo() RETURNS SETOF foo AS
$BODY$
DECLARE
r foo%rowtype;
BEGIN
FOR r IN
SELECT * FROM foo WHERE fooid > 0
LOOP
-- 这里可以做一些处理
RETURN NEXT r; -- 返回 SELECT 的当前行
END LOOP;
RETURN;
END
$BODY$
LANGUAGE plsql;
SELECT * FROM get_all_foo();
使用RETURN QUERY的函数,如下所示。
CREATE FUNCTION get_available_flightid(date) RETURNS SETOF integer AS
$BODY$
BEGIN
RETURN QUERY SELECT flightid
FROM flight
WHERE flightdate >= $1
AND flightdate < ($1 + 1);
-- 因为执行还未结束,可以检查是否有行被返回
-- 如果没有就抛出异常。
IF NOT FOUND THEN
RAISE EXCEPTION 'No flight at %.', $1;
END IF;
RETURN;
END
$BODY$
LANGUAGE plsql;
-- 返回可用的航班或者在没有可用航班时抛出异常。
SELECT * FROM get_available_flightid(CURRENT_DATE);
注意
如上所述,目前RETURN NEXT和RETURN QUERY的实现在从函数返回之前会把整个结果集都保存起来。这意味着如果一个PL/SQL函数生成一个非常大的结果集,性能可能会很差:数据将被写到磁盘上以避免内存耗尽,但是函数本身在整个结果集都生成之前不会退出。将来的PL/SQL版本可能会允许用户定义没有这种限制的集合返回函数。目前,数据开始被写入到磁盘的时机由配置变量work_mem控制。拥有足够内存来存储大型结果集的管理员可以考虑增大这个参数。
6.2.从过程中返回
过程没有返回值。因此,过程的结束可以不用RETURN语句。如果想用一个RETURN语句提前退出代码,只需写一个没有表达式的RETURN。
如果过程有输出参数,那么输出参数最终的值会被返回给调用者。
6.3.调用存储过程
PL/SQL函数,存储过程或匿名块可以调用存储用过程。调用时直接引用过程路径名,不可带关键字CALL。
-
语法
[ <<label>> ] procedure [(parameter (,parameter)*)]; -
参数
存储过程参数说明
参数 说明 label 本语句的标志(通常用于语法块标识或调试记录)。 procedure 调用的过程路径(指定存储过程的名称或包含模式名的完整路径)。 parameter 过程调用的实参(传递给存储过程的具体数值、变量或表达式)。 -
如果形参为in,实参可以是任意表达式。
-
如果形参带默认值,那么实参可以省略。
-
如果形参为out,实参必须是一个变量,其类型不能有非空的限制。
-
如果形参为 inout,实参必须是一个变量。
-
如果过程无参数,或因为默认值的原因全部省略,那么过程路径名后可以直接跟语句结束符 ‘;’,或者跟一对括号,再跟结束符,如p; p();。
-
-
示例
create or replace procedure p01 as num int :=999; procedure f3 is var1 int default 1; procedure f1(num int) is var1 int default 2; begin raise notice 'f1--var1无前缀:%',var1; raise notice 'f1--var1有前缀f1:%',f1.var1; raise notice 'f1--var1有前缀f1:外f3.var1:%',f3.var1; end; begin f1(num); raise notice '1'; end; begin f3; raise notice '1'; end; /
6.4.条件
IF和CASE语句根据某种条件执行二选其一的命令。PL/SQL有三种形式的IF,如下所示。
-
IF ... THEN ... END IF -
IF ... THEN ... ELSE ... END IF -
IF ... THEN ... ELSIF ... THEN ... ELSE ... END IF
以及两种形式的CASE:
-
CASE ... WHEN ... THEN ... ELSE ... END CASE -
CASE WHEN ... THEN ... ELSE ... END CASE
6.4.1.IF-THEN
IF boolean-expression THEN
statements
END IF;
IF-THEN语句是IF的最简单形式。如果条件为真,在THEN和END IF之间的语句将被执行。否则,将忽略它们。
示例
IF v_user_id <> 0 THEN
UPDATE users SET email = v_email WHERE user_id = v_user_id;
END IF;
6.4.2.IF-THEN-ELSE
IF boolean-expression THEN
statements
ELSE
statements
END IF;
IF-THEN-ELSE语句对IF-THEN进行了增加,它能够指定一组在条件不为真时应该被执行的语句(注意这也包括条件为NULL的情况)。
示例
IF parentid IS NULL OR parentid = ''
THEN
RETURN fullname;
ELSE
RETURN hp_true_filename(parentid) || '/' || fullname;
END IF;
IF v_count > 0 THEN
INSERT INTO users_count (count) VALUES (v_count);
RETURN 't';
ELSE
RETURN 'f';
END IF;
6.4.3.IF-THEN-ELSIF
IF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
[ ELSIF boolean-expression THEN
statements
...
]
]
[ ELSE
statements ]
END IF;
有时会有多于两种选择。IF-THEN-ELSIF则提供了一个简便的方法来检查多个条件。IF条件会被一个接一个测试,直到找到第一个为真的。然后执行相关语句,然后控制会被交给END IF之后的下一个语句(后续的任何IF条件不会被测试)。如果没有一个IF条件为真,那么ELSE块(如果有)将被执行。
示例
IF number = 0 THEN
result := 'zero';
ELSIF number > 0 THEN
result := 'positive';
ELSIF number < 0 THEN
result := 'negative';
ELSE
-- 嗯,唯一的其他可能性是数字为空
result := 'NULL';
END IF;
关键词ELSIF也可以被拼写成ELSEIF。
另一个可以完成相同任务的方法是嵌套IF-THEN-ELSE语句,如下所示。
IF demo_row.sex = 'm' THEN
pretty_sex := 'man';
ELSE
IF demo_row.sex = 'f' THEN
pretty_sex := 'woman';
END IF;
END IF;
不过,这种方法需要为每个IF都写一个匹配的END IF,因此当有很多选择时,这种方法比使用ELSIF要麻烦得多。
6.4.4.简单CASE
CASE search-expression
WHEN expression [, expression [ ... ]] THEN
statements
[ WHEN expression [, expression [ ... ]] THEN
statements
... ]
[ ELSE
statements ]
END CASE;
CASE的简单形式提供了基于操作数等值判断的有条件执行。search-expression会被计算(一次)并且一个接一个地与WHEN子句中的每个expression比较。如果找到一个匹配,那么相应的statements会被执行,并且接着控制会被交给END CASE之后的下一个语句(后续的WHEN表达式不会被计算)。如果没有找到匹配,ELSE语句会被执行。但是如果ELSE不存在,将会抛出一个CASE_NOT_FOUND异常。
示例
CASE x
WHEN 1, 2 THEN
msg := 'one or two';
ELSE
msg := 'other value than one or two';
END CASE;
6.4.5.搜索CASE
CASE
WHEN boolean-expression THEN
statements
[ WHEN boolean-expression THEN
statements
... ]
[ ELSE
statements ]
END CASE;
CASE的搜索形式基于布尔表达式真假的有条件执行。每一个WHEN子句的boolean-expression会被依次计算,直到找到一个得到真的。然后相应的statements会被执行,并且接下来控制会被传递给END CASE之后的下一个语句(后续的WHEN表达式不会被计算)。如果没有找到为真的结果,ELSE statements会被执行。但是如果ELSE不存在,那么将会抛出一个CASE_NOT_FOUND异常。
示例
CASE
WHEN x BETWEEN 0 AND 10 THEN
msg := 'value is between zero and ten';
WHEN x BETWEEN 11 AND 20 THEN
msg := 'value is between eleven and twenty';
END CASE;
这种形式的CASE整体上等价于IF-THEN-ELSIF,不同之处在于CASE到达一个被忽略的ELSE子句时会导致一个错误而不是什么也不做。
6.5.简单循环
使用LOOP、EXIT、CONTINUE、WHILE、FOR、FORALL和FOREACH语句,可以安排PL/SQL重复一系列命令。
6.5.1.LOOP
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
LOOP定义一个无条件的循环,它会无限重复直到被EXIT或RETURN语句终止。可选的label可以被EXIT和CONTINUE语句用在嵌套循环中指定这些语句引用的是哪一层循环。
6.5.2.EXIT
EXIT [ label ] [ WHEN boolean-expression ];
如果没有给出label,那么最内层的循环会被终止,然后跟在END LOOP后面的语句会被执行。如果给出了label,那么它必须是当前或者更高层的嵌套循环或者语句块的标签。然后该命名循环或块就会被终止,并且控制会转移到该循环/块相应的END之后的语句上。
如果指定了WHEN,只有boolean-expression为真时才会发生循环退出。否则,控制会转移到EXIT之后的语句。
EXIT可以被用在所有类型的循环中,它并不限于在无条件循环中使用。
在和BEGIN块一起使用时,EXIT会把控制交给块结束后的下一个语句。需要注意的是,一个标签必须被用于这个目的;一个没有被标记的EXIT永远无法被认为与一个BEGIN块匹配(这种状况已经开始改变。这可能允许一个未被标记的EXIT匹配一个BEGIN块)。
示例
LOOP
-- 一些计算
IF count > 0 THEN
EXIT; -- 退出循环
END IF;
END LOOP;
LOOP
-- 一些计算
EXIT WHEN count > 0; -- 和前一个示例相同的结果
END LOOP;
<<ablock>>
BEGIN
-- 一些计算
IF stocks > 100000 THEN
EXIT ablock; -- 导致从 BEGIN 块中退出
END IF;
-- 当stocks > 100000时,这里的计算将被跳过
END;
6.5.3.CONTINUE
CONTINUE [ label ] [ WHEN boolean-expression ];
如果没有给出label,最内层循环的下一次迭代会开始。也就是,循环体中剩余的所有语句将被跳过,并且控制会返回到循环控制表达式(如果有)来决定是否需要另一次循环迭代。如果label存在,它指定应该继续执行的循环的标签。
如果指定了WHEN,该循环的下一次迭代只有在boolean-expression为真时才会开始。否则,控制会传递给CONTINUE后面的语句。
CONTINUE可以被用在所有类型的循环中,它并不限于在无条件循环中使用。
示例
LOOP
-- 一些计算
EXIT WHEN count > 100;
CONTINUE WHEN count < 50;
-- 一些用于 count IN [50 .. 100] 的计算
END LOOP;
6.5.4.WHILE
[ <<label>> ]
WHILE boolean-expression LOOP
statements
END LOOP [ label ];
只要boolean-expression被计算为真,WHILE语句就会重复一个语句序列。在每次进入到循环体之前都会检查该表达式。
如下所示。
WHILE amount_owed > 0 AND gift_certificate_balance > 0 LOOP
-- 这里是一些计算
END LOOP;
WHILE NOT done LOOP
-- 这里是一些计算
END LOOP;
6.5.5.FOR
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
statements
END LOOP [ label ];
这种形式的FOR会创建一个在一个整数范围上迭代的循环。变量name会自动定义为类型integer并且只在循环内存在(任何该变量名的现有定义在此循环内都将被忽略)。给出范围上下界的两个表达式在进入循环的时候计算一次。如果没有指定BY子句,迭代步长为 1,否则步长是BY中指定的值,该值也只在循环进入时计算一次。如果指定了REVERSE,那么在每次迭代后步长值会被减除而不是增加。
在一个非整数范围上迭代的循环,变量name会自动定义为与结果集类型相同的类型并且只在循环内存在。
整数FOR循环,如下所示。
FOR i IN 1..10 LOOP
-- 我在循环中将取值 1,2,3,4,5,6,7,8,9,10
END LOOP;
FOR i IN REVERSE 10..1 LOOP
-- 我在循环中将取值 10,9,8,7,6,5,4,3,2,1
END LOOP;
FOR i IN REVERSE 10..1 BY 2 LOOP
-- 我在循环中将取值 10,8,6,4,2
END LOOP;
非整数FOR循环,如下所示。
for t in select * from generate_series(1,4) loop
--我在循环中将取值 (1),(2),(3),(4)
raise notice '%',t;
end loop;
如果下界大于上界(或者在REVERSE情况下是小于),循环体根本不会被执行。而且不会抛出任何错误。
如果一个label被附加到FOR循环,那么整数循环变量可以用一个使用那个label的限定名引用。
变量name可以是不同于for循环体中关键字的关键字名称,如下所示。
for rownum in 1..2 loop
--我在循环中将取值 1,2
raise notice ‘%’, rownum;
end loop;
6.5.6.FORALL
[ <<label>> ]
FORALL name IN lower_bound .. upper_bound
dml_statement
FORALL 参数说明
| 参数 | 说明 |
|---|---|
name | 一个无需显式声明的标识符,在循环体内作为下标索引使用。 |
lower_bound .. upper_bound | 数字表达式,用于指定一组连续有效的索引数字下限和上限。 |
dml_statement | 循环执行的 SQL 语句。注意:仅支持 UPDATE、INSERT、DELETE、MERGE 及 EXECUTE 语句。 |
在FORALL语句中,DML语句可以有一个RETURNING BULK COLLECT INTO子句。对于FORALL语句的每次迭代,DML语句将指定的值存储在指定的集合中,而不会覆盖以前的值。
declare
type id_tbl is table of int;
ids id_tbl;
begin
forall i in 1..100
insert into t1 values(i) returning id bulk collect into ids;
raise info 'ids=%', ids;
raise info 'SQL%%BULK_ROWCOUNT=%', SQL%BULK_ROWCOUNT;
end;
/
在FORALL语句完成后,您可以从隐式游标属性SQL%BULK_ROWCOUNT获取每个DML语句影响的行数。
FORALL示例,如下所示。
FORALL i IN 1..100
insert into t1 values(i);
变量name可以是不同于forall循环体中关键字的关键字名称,如下所示。
forall rownum in 1..2
update t1 set col1 = rownum;
6.6.通过查询结果循环
使用一种不同类型的FOR循环,可以通过一个查询的结果进行迭代并且操纵相应的数据。语法如下所示。
[ <<label>> ]
FOR target IN query LOOP
statements
END LOOP [ label ];
target是一个记录变量、行变量或者逗号分隔的标量变量列表。target被连续不断被赋予来自query的每一行,并且循环体将为每一行执行一次。如下所示。
CREATE FUNCTION refresh_mviews() RETURNS integer AS $$
BEGIN
RAISE NOTICE 'Refreshing all materialized views...';
FOR mviews IN
SELECT n.nspname AS mv_schema,
c.relname AS mv_name,
ux_catalog.ux_get_userbyid(c.relowner) AS owner
FROM ux_catalog.ux_class c
LEFT JOIN ux_catalog.ux_namespace n ON (n.oid = c.relnamespace)
WHERE c.relkind = 'm'
ORDER BY 1
LOOP
-- Now "mviews" has one record with information about the materialized view
RAISE NOTICE 'Refreshing materialized view %.% (owner: %)...',
quote_ident(mviews.mv_schema),
quote_ident(mviews.mv_name),
quote_ident(mviews.owner);
EXECUTE format('REFRESH MATERIALIZED VIEW %I.%I', mviews.mv_schema, mviews.mv_name);
END LOOP;
RAISE NOTICE 'Done refreshing materialized views.';
RETURN 1;
END;
$$ LANGUAGE plsql;
如果循环被一个EXIT语句终止,那么在循环之后仍然可以访问最后被赋予的行值。
在这类FOR语句中使用的query可以是任何返回行给调用者的 SQL 命令:最常见的是SELECT,但也可以使用带有RETURNING子句的INSERT、UPDATE或DELETE。一些EXPLAIN之类的功能性命令也可以用在这里。
PL/SQL变量会被替换到查询文本中,并且如变量替换和计划缓存中详细讨论的,查询计划会被缓存以用于可能的重用。
FOR-IN-EXECUTE语句是在行上迭代的另一种方式,如下所示。
[ <<label>> ]
FOR target IN EXECUTE text_expression [ USING expression [, ... ] ] LOOP
statements
END LOOP [ label ];
这个示例类似前面的形式,只不过源查询被指定为一个字符串表达式,在每次进入FOR循环时都会计算它并且重新规划。这允许程序员在一个预先规划好了的命令的速度和一个动态命令的灵活性之间进行选择,就像一个纯EXECUTE语句那样。在使用EXECUTE时,可以通过USING将参数值插入到动态命令中。
另一种指定要对其结果迭代的查询的方式是将它声明为一个游标。这会在通过一个游标的结果循环中描述。
6.7.通过数组循环
FOREACH循环很像一个FOR循环,但不是通过一个 SQL 查询返回的行进行迭代,它通过一个数组值的元素来迭代(通常,FOREACH意味着通过一个组合值表达式的部件迭代;用于通过除数组之外组合类型进行循环的变体可能会在未来被加入)。在一个数组上循环的FOREACH语句如下所示。
[ <<label>> ]
FOREACH target [ SLICE number ] IN ARRAY expression LOOP
statements
END LOOP [ label ];
如果没有SLICE,或者如果没有指定SLICE 0,循环会通过计算expression得到的数组的个体元素进行迭代。target变量被逐一赋予每一个元素值,并且循环体会为每一个元素执行。通过整数数组的元素循环,如下所示。
CREATE FUNCTION sum(int[]) RETURNS int8 AS $$
DECLARE
s int8 := 0;
x int;
BEGIN
FOREACH x IN ARRAY $1
LOOP
s := s + x;
END LOOP;
RETURN s;
END;
$$ LANGUAGE plsql;
元素会被按照存储顺序访问,而不管数组的维度数。尽管target通常只是一个单一变量,当通过一个组合值(记录)的数组循环时,它可以是一个变量列表。在那种情况下,对每一个数组元素,变量会被从组合值的连续列赋值。
通过一个正SLICE值,FOREACH通过数组的切片而不是单一元素迭代。SLICE值必须是一个不大于数组维度数的整数常量。target变量必须是一个数组,并且它接收数组值的连续切片,其中每一个切片都有SLICE指定的维度数。通过一维切片迭代,如下所示。
CREATE FUNCTION scan_rows(int[]) RETURNS void AS $$
DECLARE
x int[];
BEGIN
FOREACH x SLICE 1 IN ARRAY $1
LOOP
RAISE NOTICE 'row = %', x;
END LOOP;
END;
$$ LANGUAGE plsql;
SELECT scan_rows(ARRAY[[1,2,3],[4,5,6],[7,8,9],[10,11,12]]);
NOTICE: row = {1,2,3}
NOTICE: row = {4,5,6}
NOTICE: row = {7,8,9}
NOTICE: row = {10,11,12}
6.8.俘获错误
默认情况下,任何在PL/SQL函数中发生的错误会中止该函数的执行,而且实际上会中止其周围的事务。可以使用一个带有EXCEPTION子句的BEGIN块俘获错误并且从中恢复。其语法是BEGIN块通常的语法的一个扩展,如下所示。
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
EXCEPTION
WHEN condition [ OR condition ... ] THEN
handler_statements
[ WHEN condition [ OR condition ... ] THEN
handler_statements
... ]
END;
如果没有发生错误,这种形式的块只是简单地执行所有statements, 并且接着控制转到END之后的下一个语句。但是如果在statements内发生了一个错误,则会放弃对statements的进一步处理,然后控制会转到EXCEPTION列表。系统会在列表中寻找匹配所发生错误的第一个condition。如果找到一个匹配,则执行对应的handler_statements,并且接着把控制转到END之后的下一个语句。如果没有找到匹配,该错误就会传播出去,就好像根本没有EXCEPTION一样:错误可以被一个带有EXCEPTION的闭合块捕捉,如果没有EXCEPTION则中止该函数的处理。
condition的名字可以是错误代码中的任何名字。一个分类名匹配其中所有的错误。特殊的条件名OTHERS匹配除了QUERY_CANCELED和ASSERT_FAILURE之外的所有错误类型(虽然通常并不明智,还是可以用名字捕获这两种错误类型)。条件名是大小写无关的。一个错误条件也可以通过SQLSTATE代码指定,例如以下语句是等价的。
WHEN division_by_zero THEN ...
WHEN SQLSTATE '22012' THEN ...
如果在选中的handler_statements内发生了新的错误,那么它不能被这个EXCEPTION子句捕获,而是被传播出去。一个外层的EXCEPTION子句可以捕获它。
当一个错误被EXCEPTION捕获时,PL/SQL函数的局部变量会保持错误发生时的值,但是该块中所有对持久数据库状态的改变都会被回滚。例如,思考下如下语句。
INSERT INTO mytab(firstname, lastname) VALUES('Tom', 'Jones');
BEGIN
UPDATE mytab SET firstname = 'Joe' WHERE lastname = 'Jones';
x := x + 1;
y := x / 0;
EXCEPTION
WHEN division_by_zero THEN
RAISE NOTICE 'caught division_by_zero';
RETURN x;
END;
当控制到达对y赋值的地方时,它会带着一个division_by_zero错误失败。这个错误将被EXCEPTION子句捕获。而在RETURN语句中返回的值将是x增加过后的值。但是UPDATE命令的效果将已经被回滚。不过,在该块之前的INSERT将不会被回滚,因此最终的结果是数据库包含Tom Jones但不包含Joe Jones。
注意
进入和退出一个包含EXCEPTION子句的块要比不包含EXCEPTION的块开销大的多。因此,只在必要的时候使用EXCEPTION。
例 UPDATE/INSERT的异常
这个示例使用异常处理来酌情执行UPDATE或INSERT。推荐应用使用带有ON CONFLICT DO UPDATE的INSERT而不是真正使用这种模式。下面示例主要是为了展示PL/SQL如何控制流程。
CREATE TABLE db (a INT PRIMARY KEY, b TEXT);
CREATE FUNCTION merge_db(key INT, data TEXT) RETURNS VOID AS
$$
BEGIN
LOOP
-- 首先尝试更新见
UPDATE db SET b = data WHERE a = key;
IF found THEN
RETURN;
END IF;
-- 不在这里,那么尝试插入该键
-- 如果其他某人并发地插入同一个键,
-- 可能得到一个唯一键失败
BEGIN
INSERT INTO db(a,b) VALUES (key, data);
RETURN;
EXCEPTION WHEN unique_violation THEN
-- 什么也不做,并且循环再次尝试 UPDATE
END;
END LOOP;
END;
$$
LANGUAGE plsql;
SELECT merge_db(1, 'david');
SELECT merge_db(1, 'dennis');
这段代码假定unique_violation错误是INSERT造成,并且不是由该表上一个触发器函数中的INSERT导致。如果在该表上有多于一个唯一索引,也可能会发生不正确的行为,因为不管哪个索引导致该错误它都将重试该操作。通过接下来要讨论的特性来检查被捕获的错误是否为所预期的会更安全。
6.8.1.得到有关一个错误的信息
异常处理器经常被用来标识发生的特定错误。有两种方法来得到PL/SQL中当前异常的信息:特殊变量和GET STACKED DIAGNOSTICS命令。
在一个异常处理器内,特殊变量SQLSTATE包含了对应于被抛出异常的错误代码。特殊变量SQLERRM包含与该异常相关的错误消息。这些变量在异常处理器外是未定义的。
在一个异常处理器内,也可以用GET STACKED DIAGNOSTICS命令检索有关当前异常的信息,该命令的形式如下所示。
GET STACKED DIAGNOSTICS variable { = | := } item [ , ... ];
每个item是一个关键词,它标识一个被赋予给指定变量(应该具有接收该值的正确数据类型)的状态值。错误诊断项中显示了当前可用的状态项。
错误诊断项
| 名称 | 类型 | 描述 |
|---|---|---|
RETURNED_SQLSTATE | text | 该异常对应的标准 SQLSTATE 错误代码。 |
COLUMN_NAME | text | 与该异常相关的具体列名(如果适用)。 |
CONSTRAINT_NAME | text | 与该异常相关的约束名(如违反唯一约束或外键约束时的名称)。 |
UX_DATATYPE_NAME | text | 与该异常相关的数据类型名称。 |
MESSAGE_TEXT | text | 该异常的主要错误消息文本。 |
TABLE_NAME | text | 与该异常相关的表名。 |
SCHEMA_NAME | text | 与该异常相关的模式(Schema)名。 |
UX_EXCEPTION_DETAIL | text | 该异常的详细错误说明文本(如果存在)。 |
UX_EXCEPTION_HINT | text | 数据库提供的针对该异常的修复提示消息(如果存在)。 |
UX_EXCEPTION_CONTEXT | text | 描述产生异常时的调用栈(Call Stack)信息,用于追踪错误源头。 |
如果异常没有为一个项设置值,将返回一个空字符串。
示例
DECLARE
text_var1 text;
text_var2 text;
text_var3 text;
BEGIN
-- 某些可能导致异常的处理
...
EXCEPTION WHEN OTHERS THEN
GET STACKED DIAGNOSTICS text_var1 = MESSAGE_TEXT,
text_var2 = UX_EXCEPTION_DETAIL,
text_var3 = UX_EXCEPTION_HINT;
END;
6.9.获得执行位置信息
GET DIAGNOSTICS(之前在获得结果状态中描述)命令检索有关当前执行状态的信息(反之上文讨论的GET STACKED DIAGNOSTICS命令会把有关执行状态的信息报告成一个以前的错误)。它的UX_CONTEXT状态项可用于标识当前执行位置。状态项UX_CONTEXT将返回一个文本字符串,其中有描述该调用栈的多行文本。第一行会指向当前函数以及当前正在执行GET DIAGNOSTICS的命令。第二行及其后的行表示调用栈中更上层的调用函数。如下所示。
CREATE OR REPLACE FUNCTION outer_func() RETURNS integer AS $$
BEGIN
RETURN inner_func();
END;
$$ LANGUAGE plsql;
CREATE OR REPLACE FUNCTION inner_func() RETURNS integer AS $$
DECLARE
stack text;
BEGIN
GET DIAGNOSTICS stack = UX_CONTEXT;
RAISE NOTICE E'--- Call Stack ---\n%', stack;
RETURN 1;
END;
$$ LANGUAGE plsql;
SELECT outer_func();
NOTICE: --- Call Stack ---
PL/SQL function inner_func() line 5 at GET DIAGNOSTICS
PL/SQL function outer_func() line 3 at RETURN
CONTEXT: PL/SQL function outer_func() line 3 at RETURN
outer_func
------------
1
(1 row)
GET STACKED DIAGNOSTICS ... UX_EXCEPTION_CONTEXT返回同类的栈跟踪,但是它描述检测到错误的位置而不是当前位置。
6.10.goto语句
用户在使用PL/SQL的时候可以使用goto子句进行相关标签的跳转。即:GOTO语句将控制转移到带标签的块或语句,或者说,该语句使执行点跳转到具有指定标签的语句。
[ DECLARE
declarations ]
BEGIN
GOTO lable;
Statements;
<<lable>>
END;
/
GOTO语句可以用于将控制权从当前封闭语法块转移到其他语法块。GOTO标签只能出现在块之前,而不是结尾。GOTO标签后面不能直接跟EXCEPTION、END LOOP这种关键字类的语句,可以用NULL把标签跟关键字隔开。
注意
-
如果
GOTO语句过早地退出游标FOR LOOP语句,游标将关闭。 -
GOTO语句不能将控制转移到IF语句、CASE语句、LOOP语句或子块中。 -
GOTO语句不能将控制从一个IF语句子句转移到另一个,或从一个CASE语句WHEN子句转移到另一个。 -
GOTO语句不能将控制转移出子程序。 -
GOTO语句无法将控制转移到异常处理程序中。 -
GOTO语句无法将控制从异常处理程序转移回当前块(但它可以将控制从异常处理程序转移到封闭块即:父块)。 -
GOTO语句不能将控制转移到条件块或子块中,但可以从条件块或子块中转移控制。 -
GOTO语句不能跳转到声明(declaration)。 -
GOTO语句不能将控制转移到另一个函数或过程中。 -
标签(label)不应放在块、函数或过程的末尾。
示例
-- 示例1:
DECLARE
p text;
n int := 37;
BEGIN
FOR j in 2..ROUND(SQRT(n)) LOOP
IF n % j = 0 THEN
p := 'is not a prime number';
GOTO print_now;
END IF;
END LOOP;
p := ' is a prime number';
<<print_now>> --here
raise info '%',n;
raise info '%',p;
END;
/
DECLARE
p text;
n int := 36;
BEGIN
FOR j in 2..ROUND(SQRT(n)) LOOP
IF n % j = 0 THEN
p := 'is not a prime number';
GOTO print_now;
END IF;
END LOOP;
p := ' is a prime number';
<<print_now>> --here
raise info '%',n;
raise info '%',p;
END;
/
-- 示例2:
BEGIN
FOR i IN 1..50 LOOP
IF i=50 THEN
raise info '%',i;
GOTO end_loop;
END IF;
<<end_loop>>
NULL;
END LOOP;
END;
/
-- 示例3:要报错(语法不支持)
BEGIN
FOR i IN 1..50 LOOP
IF i=50 THEN
raise info '%',i;
GOTO end_loop;
END IF;
<<end_loop>>
END LOOP;
END;
/
-- 示例4:
create table employees (employee_id int, last_name text);
insert into employees values (120, 'Weiss');
insert into employees values (121, 'Weiss1');
insert into employees values (122, 'Weiss2');
insert into employees values (123, 'Weiss3');
insert into employees values (124, 'Weiss4');
DECLARE
v_last_name text;
v_emp_id int := 120;
BEGIN
<<get_name>>
SELECT last_name INTO v_last_name FROM employees WHERE employee_id = v_emp_id;
BEGIN
raise info '%',v_last_name;
v_emp_id := v_emp_id + 2;
IF v_emp_id < 125 THEN
GOTO get_name;
END IF;
END;
END;
/
drop table employees;
-- 示例5: 要报错(GOTO Statement Cannot Transfer Control into IF Statement)
DECLARE
valid bool := TRUE;
BEGIN
GOTO update_row;
IF valid THEN
<<update_row>>
NULL;
END IF;
raise info 'end';
-- 这个位置是return控制
END;
/
-- 示例6:
create procedure test111() LANGUAGE 'plsql' as $$
i integer;
begin
i := 2;
loop
<<next_step>>
i := i * 2;
if i > 100 then
exit;
end if;
if i > 50 then
raise info '%',i;
goto next_step;
end if;
raise info '%',i;
end loop;
end $$;
call test111();
drop procedure test111();
-- 示例7: 要报错(goto 不能跳转到 exception 中)
BEGIN
GOTO LB3; --expected error
EXCEPTION
WHEN OTHERS THEN
<<LB3>>
NULL;
END;
/
-- 示例8: 成功(exception 中的 goto 语句能够跳转到父块中)
DECLARE
I INT := 0;
BEGIN
<<LB1>>
I := I + 1;
raise info '%',i;
BEGIN
<<LB2>>
iF I = 1 THEN
RAISE EXCEPTION NUMERIC_VALUE_OUT_OF_RANGE;
ELSE
RAISE EXCEPTION division_by_zero;
END IF;
EXCEPTION
WHEN NUMERIC_VALUE_OUT_OF_RANGE THEN
GOTO LB1; -- 如果跳转到 LB2 则报错,即:goto 语句不能从 EXCEPTION 中跳转到当前的语句块中
WHEN division_by_zero THEN
raise info 'division_by_zero';
END;
END;
/
-- 示例9:
BEGIN
GOTO cmd1;
raise info 'i am cmd.';
<<cmd1>>
raise info 'i am cmd1.';
<<cmd2>>
raise info 'i am cmd2.';
END;
/
-- 示例10:
BEGIN
GOTO cmd1;
raise info 'i am cmd.';
<<cmd1>> raise info 'i am cmd1.';
GOTO cmd3;
<<cmd2>> raise info 'i am cmd2.';
<<cmd3>> GOTO cmd4;
<<cmd4>> raise info 'i am cmd4.';
END;
/
-- 示例11:同 Oracle,会陷入死循环
-- BEGIN
-- GOTO cmd1;
-- raise info 'i am cmd.';
-- <<cmd1>> raise info 'i am cmd1.';
-- GOTO cmd3;
-- <<cmd2>> raise info 'i am cmd2.';
-- <<cmd3>> GOTO cmd1;
-- <<cmd4>> raise info 'i am cmd4.';
-- END;
-- /
-- 示例12:goto 到 相同标签
BEGIN
GOTO cmd1;
<<cmd1>> raise info 'i am cmd1.';
<<cmd1>> raise info 'i am cmd2.';
END;
/
-- 示例13:if语句使用goto子句
create or replace function func1(t1 int) returns text
language plsql
returns null on null input
as $$
p varchar(30);
begin
if t1%2=0 then
goto even_number;
else
goto odd_number;
end if;
<<even_number>>
p := cast($1 as text) || ' is a even number';
goto end_lb;
<<odd_number>>
p := cast($1 as text) || ' is a odd number';
<<end_lb>>
return p;
end;
$$;
select func1(10);
drop function func1 ;
declare
p text;
n int := 39;
begin
for j in 2..round(sqrt(n)) loop
if n % j = 0 then
p := 'is not a prime number';
goto check_odd;
end if;
end loop;
p := ' is a prime number';
<<check_odd>> --here
begin
raise info '% %',n,p;
if n%2=0 then
p := 'is a even number';
else
p := 'is a odd number';
raise info '% %',n,p;
end if;
end;
end;
/
create or replace function function1(a int, b int)
returns int is
$$
begin
return a + b;
end;
$$
language plsql;
create or replace function function2(a int, b int)
returns int is
$$
begin
if a>b then
return a - b;
else
goto lb;
end if;
<<lb>>
return function1(a, b);
end;
$$
language plsql;
select function2(2,4);
drop function function1 ;
drop function function2 ;
7.游标
和一次执行整个查询不同,可以建立一个游标来封装该查询,并且接着一次读取该查询结果的一些行。这样做的原因之一是在结果中包含大量行时避免内存不足(不过,PL/SQL用户通常不需要担心这些,因为FOR循环在内部会自动使用一个游标来避免内存问题)。一种更有趣的用法是返回一个函数已经创建的游标的引用,允许调用者读取行。这提供了一种有效的方法从函数中返回大型行集。
7.1.声明游标变量
所有在PL/SQL中对游标的访问都会通过游标变量,它总是特殊的数据类型refcursor。创建游标变量的一种方法是把它声明为一个类型为refcursor的变量。另外一种方法是使用游标声明语法,如下所示。
name [ [ NO ] SCROLL ] CURSOR [ ( arguments ) ] FOR query;
(为了对Oracle的兼容性,可以用IS替代FOR)。如果指定了SCROLL,那么游标可以反向滚动;如果指定了NO SCROLL,那么反向取的动作会被拒绝;如果二者都没有被指定,那么能否进行反向取就取决于查询。如果指定了arguments,那么它是一个逗号分隔的name datatype对的列表,它们定义在给定查询中要被参数值替换的名称。实际用于替换这些名字的值将在游标被打开之后指定。
示例
DECLARE
curs1 refcursor;
curs2 CURSOR FOR SELECT * FROM tenk1;
curs3 CURSOR (key integer) FOR SELECT * FROM tenk1 WHERE unique1 = key;
所有这三个变量都是refcursor类型,但是第一个可以用于任何查询,而第二个已经被绑定了一个完全指定的查询,并且最后一个被绑定了一个参数化查询。(游标被打开时,key将被一个整数参数值替换)。变量curs1被称为未绑定,因为它没有被绑定到任何特定查询。
7.1.1.显式游标声明和定义
显式游标是指向私有 SQL 区域的命名指针,该区域存储用于处理特定查询或 DML 语句的信息(通常是返回或影响多行的查询或DML语句)。可以使用显式游标一次检索一个结果集的行。
在使用显式游标之前,必须声明并定义它。您可以先声明它(使用cursor_declaration),然后在同一块、子程序或包中定义它(使用cursor_definition),或者同时声明和定义它(使用cursor_definition)。
-
显式游标语法
游标声明
CURSOR cursor_name [([cursor_parameter_dec][, ...])] RETURN rowtype;游标定义
CURSOR cursor_name [([cursor_parameter_dec][, ...])] [ RETURN rowtype ] IS select_statement;-
cursor_parameter_decparameter_name [IN] datatype [{:= | DEFAULT} expression] -
rowtype{db_table_or_view | cursor | cursor_variable} % ROWTYPE
-
-
支持的功能
** 显式游标支持的功能**
序号 功能项 功能描述 1 游标声明和定义 在使用显式游标之前,必须声明并定义它。可以先声明它,然后在同一块、子程序或包中定义它或者同时声明和定义它 2 显式游标参数 1. 支持用默认值,当使用指定默认值时,open游标时可以不需要指定参数值
2. 游标参数作用域,只在该游标中使用
3. 支持显式游标参数,可以不出现在select语句中
3 select_statement部分 1. 支持游标参数,可以不出现在select_statement语句中
2. 可以使用类似于with emp_data as (select * from emp) select * from emp_data;的select语句
3. 显式游标可以引用其作用域中的任何变量
4. 支持子查询
4 显式游标使用return子句 1. db_table_or_view%ROWTYPE
2. cursor%ROWTYPE
3. cursor_variable%ROWTYPE
5 定义的游标是否支持创建为rowtype类型 使用cursor_name%rowtype创建变量 CURSOR c1 IS SELECT employee_id,(salary * .05) raise FROM employees WHERE job_id LIKE '%_MAN' ORDER BY employee_id; emp_rec c1%ROWTYPE;
6 必须为显式游标的查询中包含的虚拟列(表达式)指定别名的情况 1. 需要使用显式游标%ROWTYPE 声明记录类型变量
2. 需要在程序中引用虚拟列或表达式
-
示例
-- 创建表emp drop table emp; create table emp (empno int, ename varchar(30), deptno int, sal int); insert into emp values(1, 'zs', 101, 1000); insert into emp values(2, 'ls', 102, 2000); insert into emp values(3, 'ww', 103, 3000); insert into emp values(4, 'ws', 104, 4000); insert into emp values(5, 'tim', 105, 5000); insert into emp values(6, 'sd', 101, 1000); insert into emp values(7, 'rb', 101, 4000); insert into emp values(8, 'jsy', 104, 4000); -- 创建表dept drop table dept; create table dept(deptno int, dname varchar(30)); insert into dept values(101, 'room_101'); insert into dept values(102, 'room_102'); insert into dept values(103, 'room_103'); insert into dept values(104, 'room_104'); insert into dept values(105, 'room_105'); -- 显式游标 DO $$ DECLARE cursor cursor_name(p1 emp.empno%type := 1, p2 emp.ename%type default 'zs') is select * from emp where empno = p1 and ename = p2; -- 定义变量来存储游标返回的数据 variable1 emp%rowtype; variable2 cursor_name%rowtype; begin -- 参数值完整 OPEN cursor_name (2,'ls'); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值部分缺省 OPEN cursor_name (1); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; -- 指定参数名赋值 OPEN cursor_name (p2 => 'ww', p1 := 3); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; -- 混合赋值 OPEN cursor_name (4, p2 => 'ws'); LOOP FETCH cursor_name INTO variable2; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable2.empno: %, variable2.ename: %, variable2.sal: %', variable2.empno, variable2.ename, variable2.sal; END LOOP; CLOSE cursor_name; --参数值部分缺省 OPEN cursor_name (1); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值全部使用默认值 带括号 OPEN cursor_name (); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值全部使用默认值 不带括号 OPEN cursor_name; LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; end; $$; 结果: NOTICE: variable1.empno: 2, variable1.ename: ls, variable1.sal: 2000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 3, variable1.ename: ww, variable1.sal: 3000 NOTICE: variable2.empno: 4, variable2.ename: ws, variable2.sal: 4000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000
7.1.2.游标变量的定义与声明
游标变量类似于显式游标,不同之处在于:它不限于一个查询,可以为查询打开游标变量,处理结果集,然后将该游标变量用于另一个查询及不能接受参数。
对游标变量的限制,如下所示。
-
不能在游标
FOR LOOP语句中使用游标变量。 -
不能在包规范中声明游标变量。
-
不能将游标变量的值存储在集合或数据库列中。
-
不能使用比较运算符来测试游标变量。
-
目前暂不支持包中使用游标变量。
要创建游标变量,请声明预定义类型SYS_REFCURSOR的变量,或定义REF CURSOR类型,然后声明该类型的变量。
REF CURSOR类型定义的基本语法如下所示。
TYPE type IS REF CURSOR
[ RETURN
{ {db_table_or_view | cursor | cursor_variable}%ROWTYPE
| record%TYPE
| record_type
| ref_cursor_type
}
] ;
强游标变量与弱游标变量:如果指定 return_type ,则 REF CURSOR 类型和该类型的游标变量是强变量;如果没有,就是弱变量。SYS_REFCURSOR 和该类型的游标变量都是弱游标变量使用强游标变量,可以仅关联返回指定类型的查询。使用弱游标变量,可以关联任何查询。
sys_refcursor是系统预定义的弱游标变量。
声明游标变量如下所示。
cursor_variable type;
7.2.打开游标
在一个游标可以被用来检索行之前,它必需先被打开(这是和SQL命令DECLARE CURSOR等效的操作)。PL/SQL有三种形式的OPEN命令,其中两种用于未绑定游标变量,另外一种用于已绑定的游标变量。
注意
可以通过通过一个游标的结果循环中描述的FOR语句在不显式打开游标的情况下使用已绑定的游标变量。
7.2.1.OPEN FOR query
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR query;
该游标变量被打开并且被给定要执行的查询。游标不能是已经打开的,并且它必需已经被声明为一个未绑定的游标变量(也就是声明为一个简单的refcursor变量)。该查询必须是一条SELECT或者其它返回行的东西(例如EXPLAIN)。该查询会按照其它PL/SQL中的SQL命令同等的方式对待:先代换PL/SQL变量名,并且执行计划会被缓存用于可能的重用。当一个PL/SQL变量被替换到游标查询中时,替换的值是在OPEN时它所具有的值。对该变量后续的改变不会影响游标的行为。对于一个已经绑定的游标,SCROLL和NO SCROLL选项具有相同的含义。
示例
OPEN curs1 FOR SELECT * FROM foo WHERE key = mykey;
7.2.2.OPEN FOR EXECUTE
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR [EXECUTE] query_string
[ USING [ in | out | inout ] expression [, ... ] ];
打开游标变量并且执行指定的查询。该游标不能是已打开的,并且必须已经被声明为一个未绑定的游标变量(也就是声明为一个简单的refcursor变量)。该查询以和EXECUTE中相同的方式被指定为一个字符串表达式。照例,这提供了灵活性,因此查询计划可以在两次运行之间变化(见计划缓存),并且它也意味着在该命令字符串上还没有完成变量替换。正如EXECUTE,可以通过format()和USING将参数值插入到动态命令中。SCROLL和NO SCROLL选项具有和已绑定游标相同的含义。
绑定参数的参数模式。IN绑定参数将其值传递给指定的查询。OUT绑定参数并存储查询返回的值。IN OUT绑定参数将其初始值传递给指定的查询,并存储指定的查询返回的值。默认值:IN。
在如下示例中,表名被通过format()插入到查询中。col1的比较值被通过一个USING参数插入,所以它不需要引用。
OPEN curs1 FOR EXECUTE format('SELECT * FROM %I WHERE col1 = $1',tabname) USING keyvalue;
7.2.3.打开一个显式游标
OPEN语句打开一个显式游标,分配数据库资源来处理关联的查询,标识结果集,并将游标定位在结果集的第一行之前。
-
打开语法
OPEN cursor_name [ ( [[actual_cursor_parameter := ] actual_cursor_parameter_value] [, ...] ) ];-
cursor_name
未打开的显式游标的名称。
-
actual_cursor_parameter
正在打开的游标的实际参数列表。实际参数可以是常量、初始化变量、文字或表达式。每个实参的数据类型必须与相应形参的数据类型兼容。
可以使用位置表示法或命名表示法指定实际的游标参数。
如果游标指定了参数的默认值,则可以从参数列表中省略该参数。如果游标没有参数,或者为每个参数指定了默认值,则可以省略参数列表或指定空参数列表。
-
-
支持的功能
显式游标支持功能
序号 功能项 UXDB 支持情况说明 1 显式游标参数赋值 1. 指定赋值:支持在 OPEN游标时,使用参数名 => xx或参数名 := xx的形式给变量赋值。 2. 混合赋值:支持在OPEN游标时,将位置符号(按顺序赋值)与命名符号混合使用。 3. 无参调用:若游标定义时没有参数,OPEN时支持加空括号(即OPEN cursor_name())。2 显式游标默认值 支持默认值参数:游标定义时可设定参数默认值。使用默认值时, OPEN操作可以省略对应的参数传递。3 FOR UPDATE 子句 行级锁定:在执行 FETCH语句时,数据库会自动锁定结果集当前指向的行,确保并发环境下的数据一致性。 -
示例
-- 创建表emp drop table emp; create table emp (empno int, ename varchar(30), deptno int, sal int); insert into emp values(1, 'zs', 101, 1000); insert into emp values(2, 'ls', 102, 2000); insert into emp values(3, 'ww', 103, 3000); insert into emp values(4, 'ws', 104, 4000); insert into emp values(5, 'tim', 105, 5000); insert into emp values(6, 'sd', 101, 1000); insert into emp values(7, 'rb', 101, 4000); insert into emp values(8, 'jsy', 104, 4000); -- 创建表dept drop table dept; create table dept(deptno int, dname varchar(30)); insert into dept values(101, 'room_101'); insert into dept values(102, 'room_102'); insert into dept values(103, 'room_103'); insert into dept values(104, 'room_104'); insert into dept values(105, 'room_105'); -- 显式游标 DO $$ DECLARE cursor cursor_name(p1 emp.empno%type := 1, p2 emp.ename%type default 'zs') is select * from emp where empno = p1 and ename = p2; -- 定义变量来存储游标返回的数据 variable1 emp%rowtype; variable2 cursor_name%rowtype; begin -- 参数值完整 OPEN cursor_name (2,'ls'); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值部分缺省 OPEN cursor_name (1); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; -- 指定参数名赋值 OPEN cursor_name (p2 => 'ww', p1 := 3); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; -- 混合赋值 OPEN cursor_name (4, p2 => 'ws'); LOOP FETCH cursor_name INTO variable2; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable2.empno: %, variable2.ename: %, variable2.sal: %', variable2.empno, variable2.ename, variable2.sal; END LOOP; CLOSE cursor_name; --参数值部分缺省 OPEN cursor_name (1); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值全部使用默认值 带括号 OPEN cursor_name (); LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; --参数值全部使用默认值 不带括号 OPEN cursor_name; LOOP FETCH cursor_name INTO variable1; EXIT WHEN NOT FOUND; -- 处理每一行数据 RAISE NOTICE 'variable1.empno: %, variable1.ename: %, variable1.sal: %', variable1.empno, variable1.ename, variable1.sal; END LOOP; CLOSE cursor_name; end; $$; 结果: NOTICE: variable1.empno: 2, variable1.ename: ls, variable1.sal: 2000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 3, variable1.ename: ww, variable1.sal: 3000 NOTICE: variable2.empno: 4, variable2.ename: ws, variable2.sal: 4000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000 NOTICE: variable1.empno: 1, variable1.ename: zs, variable1.sal: 1000
7.2.4.游标变量的打开与关闭
声明游标变量后,可以使用OPEN FOR语句打开它,该语句执行以下操作。
-
将游标变量与查询关联(通常,查询返回多行)。
-
查询可以包含绑定变量的占位符,其值在
OPEN FOR语句的USING子句中指定。
在重新打开游标变量之前无需关闭它(即在另一个OPEN FOR语句中使用它)。重新打开游标变量后,之前与其关联的查询将丢失。当不再需要游标变量时,使用CLOSE语句将其关闭,从而允许重用其资源。关闭游标变量后,您无法从其结果集中获取记录或引用其属性。如果您尝试,PL/SQL会引发预定义异常INVALID_CURSOR 。
7.2.5.游标变量赋值
-
功能
Plsql中的游标赋值是指可以将另一个PL/SQL游标变量的值分配给另一个PL/SQL游标变量。
-
语法
target_cursor_variable := source_cursor_variable; -
行为说明
如果源变量是打开的,那么在分配之后,目标变量也是打开的。这两个游标变量指向同一个SQL工作区域。如果源变量未打开,则在分配后打开目标cursor变量,也不会打开源变量。
在进行游标变量赋值的时候会对右值进行校验。
-
限制
游标变量赋值语句的右表达式仅能是游标变量,显示游标不能作为源游标变量,被赋值的游标变量如果是强游标变量则需与源游标变量的返回类型相同。
7.3.使用游标
一旦一个游标已经被打开,那么就可以用这里描述的语句操作它。
这些操作不需要发生在打开该游标开始操作的同一个函数中。可以从一个函数返回一个refcursor值,并且让调用者在该游标上操作(在内部,refcursor值只是一个包含该游标活动查询的所谓入口的字符串名称。这个名字可以被传递、赋予给其它refcursor变量等等,而不用担心扰乱入口)。
所有入口会在事务的结尾被隐式地关闭。因此一个refcursor值只能在该事务结束前用于引用一个打开的游标。
7.3.1.FETCH
FETCH [ direction { FROM | IN } ] cursor INTO target;
就像SELECT INTO一样,FETCH从游标中检索下一行到目标中,目标可以是一个行变量、记录变量或者逗号分隔的简单变量列表。如果没有下一行,目标会被设置为NULL。与SELECT INTO一样,可以检查特殊变量FOUND来看一行是否被获得。
direction子句可以是SQL FETCH命令中允许的任何变体,除了那些能够取得多于一行的。即它可以是NEXT、PRIOR、FIRST、LAST、ABSOLUTE count、RELATIVE count、FORWARD或者 BACKWARD。省略direction和指定NEXT是一样的。在使用count的形式中,count可以是任意的整数值表达式(与SQL命令FETCH不一样,FETCH仅允许整数常量)。除非游标被使用SCROLL选项声明或打开,否则要求反向移动的direction值很可能会失败。
cursor必须是一个引用已打开游标入口的refcursor变量名。
游标变量的返回类型必须与FETCH语句的into_clause兼容。
示例
FETCH curs1 INTO rowvar;
FETCH curs2 INTO foo, bar, baz;
FETCH LAST FROM curs3 INTO x, y;
FETCH RELATIVE -2 FROM curs4 INTO x;
FETCH语句从多行查询的结果集中(一次一行、一次多行或一次所有行)检索数据行,并将数据存储在变量、记录或集合中。
-
取一行数据
FETCH [ direction { FROM | IN } ] [cursor|cursor_variable] INTO target;就像
SELECT INTO一样,FETCH从游标中检索下一行到目标中,目标可以是一个行变量、记录变量或者逗号分隔的简单变量列表。如果没有下一行,目标会被设置为NULL。与SELECT INTO一样,可以检查特殊变量FOUND来看一行是否被获得。direction子句可以是SQL
FETCH命令中允许的任何变体,除了那些能够取得多于一行的。即它可以是NEXT、PRIOR、FIRST、LAST、ABSOLUTE count、RELATIVE count、FORWARD或者BACKWARD。省略direction和指定NEXT是一样的。在使用count的形式中,count可以是任意的整数值表达式(与SQL命令FETCH不一样,FETCH仅允许整数常量)。除非游标被使用SCROLL选项声明或打开,否则要求反向移动的direction值很可能会失败。cursor或cursor_variable必须是一个引用已打开游标入口的refcursor变量名。
示例
FETCH curs1 INTO rowvar; FETCH curs2 INTO foo, bar, baz; FETCH LAST FROM curs3 INTO x, y; FETCH RELATIVE -2 FROM curs4 INTO x; FETCH curs3 INTO record_var; -
取多行数据
FETCH [cursor|cursor_variable] [bulk_collect_into_caluse {limit numeric_expression}]; bulk_collect_into_clause 取值如下: BULK COLLECT INTO collection[, …]用bulk_collect_into_clause可以将
FETCH返回的多行数据存储到一个或多个集合中。要让
FETCH语句一次检索所有行,请省略LIMIT numeric_expression。FETCH要限制语句一次检索的行数,请指定LIMIT numeric_expression。当
FETCH语句需要隐式数据类型转换时,bulk_collect_into_clause只能有一个collection。type numtab is table of emp%rowtype index by int; empids numtab; FETCH curs4 BULK COLLECT INTO empids; FETCH curs5 BULK COLLECT INTO empids LIMIT 2;
7.3.2.MOVE
MOVE [ direction { FROM | IN } ] cursor;
MOVE重新定位一个游标而不检索任何数据。MOVE的工作方式与FETCH命令很相似,但是MOVE只是重新定位游标并且不返回至移动到的行。与SELECT INTO一样,可以检查特殊变量FOUND来看要移动到的行是否存在。
示例
MOVE curs1;
MOVE LAST FROM curs3;
MOVE RELATIVE -2 FROM curs4;
MOVE FORWARD 2 FROM curs4;
7.3.3.UPDATE/DELETE WHERE CURRENT OF
UPDATE table SET ... WHERE CURRENT OF cursor;
DELETE FROM table WHERE CURRENT OF cursor;
当一个游标被定位到一个表行上时,使用该游标标识该行就可以对它进行更新或删除。对于游标的查询可以是什么是有限制的(尤其是不能有分组),并且最好在游标中使用FOR UPDATE。详见《优炫数据库管理系统SQL命令手册》中的DECLARE命令。
示例
UPDATE foo SET dataval = myval WHERE CURRENT OF curs1;
7.3.4.CLOSE
CLOSE cursor;
CLOSE关闭一个已打开游标的底层入口。这样就可以在事务结束之前释放资源,或者释放掉该游标变量以便再次打开。
示例
CLOSE curs1;
7.3.5.返回游标
PL/SQL函数可以向调用者返回游标。这对于返回多行或多列(特别是巨大的结果集)很有用。要想这么做,该函数打开游标并且把该游标的名字返回给调用者(或者简单的使用调用者指定的或已知的入口名打开游标)。调用者接着可以从游标中取得行。游标可以由调用者关闭,或者是在事务关闭时自行关闭。
用于一个游标的入口名可以由编程者指定或者自动生成。要指定一个入口名,只需要在打开refcursor变量之前简单地为它赋予一个字符串。OPEN将把refcursor变量的字符串值用作底层入口的名字。不过,如果refcursor变量为空,OPEN会自动生成一个与任何现有入口不冲突的名称,并且将它赋予给refcursor变量。
注意
一个已绑定的游标变量被初始化为表示其名称的字符串值,因此入口的名字和游标变量名相同,除非程序员在打开游标之前通过赋值覆盖了这个名字。但是一个未绑定的游标变量最初默认为空值,因此它会收到一个自动生成的唯一名字,除非被覆盖。
下面的示例显示了一个调用者提供游标名字的方法。
CREATE TABLE test (col text);
INSERT INTO test VALUES ('123');
CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
BEGIN
OPEN $1 FOR SELECT col FROM test;
RETURN $1;
END;
' LANGUAGE plsql;
BEGIN;
SELECT reffunc('funccursor');
FETCH ALL IN funccursor;
COMMIT;
下面的示例使用了自动游标名生成。
CREATE FUNCTION reffunc2() RETURNS refcursor AS '
DECLARE
ref refcursor;
BEGIN
OPEN ref FOR SELECT col FROM test;
RETURN ref;
END;
' LANGUAGE plsql;
-- 需要在一个事务中使用游标。
BEGIN;
SELECT reffunc2();
reffunc2
--------------------
<unnamed cursor 1>
(1 row)
FETCH ALL IN "<unnamed cursor 1>";
COMMIT;
下面的示例展示了从一个函数中返回多个游标的一种方法。
CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
BEGIN
OPEN $1 FOR SELECT * FROM table_1;
RETURN NEXT $1;
OPEN $2 FOR SELECT * FROM table_2;
RETURN NEXT $2;
END;
$$ LANGUAGE plsql;
-- 需要在一个事务中使用游标。
BEGIN;
SELECT * FROM myfunc('a', 'b');
FETCH ALL FROM a;
FETCH ALL FROM b;
COMMIT;
7.4.通过一个游标的结果循环
有一种FOR语句的变体,它允许通过游标返回的行进行迭代。语法结构如下所示。
[ <<label>> ]
FOR recordvar IN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ] LOOP
statements
END LOOP [ label ];
该游标变量必须在声明时已经被绑定到某个查询,并且它不能已经被打开。FOR语句会自动打开游标,并且在退出循环时自动关闭游标。当且仅当游标被声明要使用参数时,才必须出现一个实际参数值表达式的列表。这些值会被替换到查询中,采用OPEN期间的方式(见打开一个显式游标)。
变量recordvar会被自动定义为record类型,并且只存在于循环内部(循环中该变量名任何已有定义都会被忽略)。每一个由游标返回的行都会被陆续地赋值给这个记录变量并且执行循环体。
7.5.游标属性
7.5.1.显式游标属性
显式游标需要使用DECLARE语句显式声明和定义。
显式游标的控制和访问需要通过OPEN、FETCH和CLOSE等显式操作来控制游标的打开、检索和关闭。
显式游标的使用范围:用于处理返回多行数据的SELECT查询。
显式游标属性的功能,如下表所示。
显式游标功能
| 属性名称 | 功能描述 |
|---|---|
named_cursor%ISOPEN | 检查状态:如果游标已打开,返回 TRUE;否则返回 FALSE。 |
named_cursor%FOUND | 获取结果:如果最近一次 FETCH 成功获取了至少一行数据,返回 TRUE;否则返回 FALSE。 |
named_cursor%NOTFOUND | 获取结果:如果最近一次 FETCH 没有获取到任何行(即数据已读完),返回 TRUE;否则返回 FALSE。 |
named_cursor%ROWCOUNT | 行数统计:返回到目前为止从该游标中获取的总行数。 |
显式游标属性支持同时查询多个显式游标的属性;若显式游标未打开或者已关闭,除了named_cursor%ISOPEN属性外,都会引发预定义的异常INVALID CURSOR。
7.5.1.1.ISOPEN
-
语法
named_cursor%ISOPEN -
功能
打开游标之后,且关闭游标之前,返回
TRUE;打开游标之前或者关闭游标之后,返回FALSE。 -
参数
named_cursor指的是通过
DECLARE语句定义的显式游标的名称。 -
返回值
返回布尔型
BOOLEAN。
7.5.1.2.FOUND
-
语法
named_cursor%FOUND -
功能
如果游标打开,但没有尝试取,则返回
NULL。如果最近一次FETCH语句成功获取了至少一行数据,则返回TRUE,否则返回FALSE。 -
参数
named_cursor指的是通过
DECLARE语句定义的显式游标的名称。 -
返回值
返回布尔型
BOOLEAN。 -
注意
打开游标之前,或者关闭游标之后,调用此参数,会显示报错信息invalid cursor。
7.5.1.3.NOTFOUND
-
语法
named_cursor%NOTFOUND -
功能
如果游标打开,但没有尝试取,则返回
NULL。如果最近一次FETCH语句未成功获取任何行数据,则返回TRUE,否则返回FALSE。 -
参数
named_cursor指的是通过
DECLARE语句定义的显式游标的名称。 -
返回值
返回布尔型
BOOLEAN。 -
注意
打开游标之前,或者关闭游标之后,调用此参数,会显示报错信息invalid cursor。
7.5.1.4.ROWCOUNT
-
语法
named_cursor%ROWCOUNT -
功能
如果游标打开,但没有尝试取,则返回0。如果打开游标且尝试取之后,表示迄今已获取的行数。
-
参数
named_cursor指的是通过
DECLARE语句定义的显式游标的名称。 -
返回值
返回数值型
INTEGER。 -
注意
打开游标之前,或者关闭游标之后,调用此参数,会显示报错信息invalid cursor。
7.5.2.隐式游标属性
隐式游标无需显式声明,由SQL语句自动创建。
隐式游标的控制和访问:当执行SQL查询时,UXDB会自动打开游标、检索数据并关闭游标。
隐式游标的使用范围:用于处理DML语句和返回单行数据的SELECT查询。
隐式游标属性如下所示。
7.5.2.1.ISOPEN
-
语法
SQL%ISOPEN -
功能
判断隐式游标是否已经打开。对用户而言,该属性值始终为
FALSE,因为操作时系统自动打开,操作完后立即自动关闭。 -
返回值
返回布尔型
BOOLEAN。
7.5.2.2.FOUND
-
语法
SQL%FOUND -
功能
如果没有
SELECT或DML语句运行,则为NULL。如果最近的
SELECT或DML语句至少返回一行,则为TRUE。如果最近的
SELECT或DML语句没有返回行,则为FALSE。 -
返回值
返回布尔型
BOOLEAN。
7.5.2.3.NOTFOUND
-
语法
SQL%NOTFOUND -
功能
如果没有
SELECT或DML语句运行,则为NULL。如果最近的
SELECT或DML语句返回一行,则为FALSE。如果最近的
SELECT或DML语句没有返回一行,则为TRUE。 -
返回值
返回布尔型
BOOLEAN。
7.5.2.4.ROWCOUNT
-
语法
SQL%ROWCOUNT -
功能
如果没有
SELECT或DML语句运行,则为NULL。如果运行了
SELECT或DML语句,则表示到目前为止获取的行数。 -
返回值
返回数值型
INTEGER。
8.事务管理
在由CALL命令调用的过程中以及匿名代码块(DO命令)中,可以用命令COMMIT和ROLLBACK结束事务(ORACLE模式下,还可以在由SELECT命令调用的函数中使用)。在一个事务被使用这些命令结束后,一个新的事务会被自动开始,因此没有单独的START TRANSACTION命令(注意BEGIN和END在PL/SQL中有不同的含义)。
这里是一个简单的示例。
CREATE PROCEDURE transaction_test1()
LANGUAGE plsql
AS $$
BEGIN
FOR i IN 0..9 LOOP
INSERT INTO test1 (a) VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
END
$$;
CALL transaction_test1();
新事务开始时具有默认事务特征,如事务隔离级别。在循环中提交事务的情况下,可能需要以与前一个事务相同的特征来自动启动新事务。命令COMMIT AND CHAIN和ROLLBACK AND CHAIN可以完成此操作。
在标准模式和MYSQL模式下,只有在从顶层调用的CALL或DO中才能进行事务控制,在没有任何其他中间命令的嵌套CALL或DO调用中也能进行事务控制。例如,如果调用栈是CALL proc1() [rarr ] CALL proc2() [rarr ] CALL proc3(),那么第二个和第三个过程可以执行事务控制动作。但是如果调用栈是CALL proc1() [rarr ] SELECT func2() [rarr ] CALL proc3(),则最后一个过程不能做事务控制,因为中间有SELECT。
在ORACLE模式下,顶层调用的CALL或DO或SELECT能进行事务控制,除此之外,任何嵌套的,以及在事务块(子事务块除外)中的CALL或DO或SELECT也能进行事务控制。例如,如果调用栈是CALL proc1() → SELECT func2() → CALL proc3(),那么第一个和第三个过程可以执行事务控制动作,第二个函数中也能执行事务控制动作。在事务块中的CALL或DO或SELECT进行事务控制时,将会自动开启具有当前事务块相同特征的事务块。
对于游标循环有特殊的考虑。如下所示。
CREATE PROCEDURE transaction_test2()
LANGUAGE plsql
AS $$
DECLARE
r RECORD;
BEGIN
FOR r IN SELECT * FROM test2 ORDER BY x LOOP
INSERT INTO test1 (a) VALUES (r.x);
COMMIT;
END LOOP;
END;
$$;
CALL transaction_test2();
通常,游标会在事务提交时被自动关闭。但是,一个作为循环的组成部分创建的游标会自动被第一个COMMIT或ROLLBACK转变成一个可保持游标。这意味着该游标在第一个COMMIT或ROLLBACK处会被完全计算出来,而不是逐行被计算。该游标在循环后仍会被自动删除,因此这通常对用户是不可见的。
有非只读命令(UPDATE ... RETURNING)驱动的游标循环中不允许有事务命令。
在标准模式和MYSQL模式下,事务在一个具有异常处理部分的块中不能被结束;在ORACLE模式下则能被结束。ORACLE模式下,如果事务控制动作在异常捕捉之后,则事务控制动作会被忽略;否则事务控制动作正常执行。
9.错误和消息
9.1.报告错误和消息
使用RAISE语句报告消息以及抛出错误。
RAISE [ level ] 'format' [, expression [, ... ]] [ USING option = expression [, ... ] ];
RAISE [ level ] condition_name [ USING option = expression [, ... ] ];
RAISE [ level ] SQLSTATE 'sqlstate' [ USING option = expression [, ... ] ];
RAISE [ level ] USING option = expression [, ... ];
RAISE ;
level选项指定了错误的严重性。允许的级别有DEBUG、LOG、INFO、NOTICE, WARNING以及EXCEPTION,默认级别是EXCEPTION。EXCEPTION会抛出一个错误(通常会中止当前事务)。其他级别仅仅是产生不同优先级的消息。不管一个特定优先级的消息是被报告给客户端、还是写到服务器日志、亦或是二者同时都做,这都由log_min_messages和client_min_messages配置变量控制。
如果有level,在它后面可以写一个format(它必须是一个简单字符串而不是表达式)。该格式字符串指定要被报告的错误消息文本。在格式字符串后面可以跟上可选的要被插入到该消息的参数表达式。在格式字符串中,%会被下一个可选参数的值所替换。写%%可以发出一个字面的%。参数的数量必须匹配格式字符串中%占位符的数量,否则在函数编译期间就会发生错误。
在这个示例中,v_job_id的值将替换字符串中的%。
RAISE NOTICE 'Calling cs_create_job(%)', v_job_id;
通过写一个后面跟着option = expression项的USING,可以为错误报告附加一些额外信息。每一个expression可以是任意字符串值的表达式。允许如下option关键词。
-
MESSAGE设置错误消息文本。这个选项可以被用于在
USING之前包括一个格式字符串的RAISE形式。 -
DETAIL提供一个错误的细节消息。
-
HINT提供一个提示消息。
-
ERRCODE指定要报告的错误代码(
SQLSTATE),或者直接作为一个五字符的SQLSTATE代码。 -
COLUMN CONSTRAINT DATATYPE TABLE SCHEMA提供一个相关对象的名称。
用给定的错误消息和提示中止事务,如下所示。
RAISE EXCEPTION 'Nonexistent ID --> %', user_id
USING HINT = 'Please check your user ID';
设置SQLSTATE有两种等价的方法,如下所示。
RAISE 'Duplicate user ID: %', user_id USING ERRCODE = 'unique_violation';
RAISE 'Duplicate user ID: %', user_id USING ERRCODE = '23505';
还有第二种RAISE语法,在其中主要参数是要被报告的条件名或SQLSTATE,如下所示。
RAISE division_by_zero;
RAISE SQLSTATE '22012';
在这种语法中,USING能被用来提供一个自定义的错误消息、细节或提示。另一种做前面的示例的方法如下所示。
RAISE unique_violation USING MESSAGE = 'Duplicate user ID: ' || user_id;
仍有另一种变体是写RAISE USING或者RAISE level USING并且把所有其他东西都放在USING列表中。
RAISE的最后一种变体根本没有参数。这种形式只能被用在一个BEGIN块的EXCEPTION子句中,它导致当前正在被处理的错误被重新抛出。
注意
没有参数的RAISE被解释为重新抛出来自包含活动异常处理器的块的错误。因此一个嵌套在那个处理器中的EXCEPTION子句无法捕捉它,即使RAISE位于嵌套EXCEPTION子句的块中也是这样。这种行为很奇怪,也并不兼容 Oracle 的 PL/SQL。
如果在一个RAISE EXCEPTION命令中没有指定条件名以及SQLSTATE,默认是使用ERRCODE_RAISE_EXCEPTION (P0001)。如果没有指定消息文本,默认是使用条件名或SQLSTATE作为消息文本。
注意
当用SQLSTATE代码指定一个错误代码时,不会受到预定义错误代码的限制,而是可以选择任何由五位以及大写 ASCII 字母构成的错误代码,只有00000不能使用。推荐尽量避免抛出以三个零结尾的错误代码,因为这些是分类代码并且只能用来捕获整个类别。
9.2.检查断言
ASSERT语句是一种向 PL/SQL函数中插入调试检查的方便方法。
ASSERT condition [ , message ];
condition是一个布尔表达式,它被期望总是计算为真。如果确实如此,ASSERT语句不会再做什么。但如果结果是假或者空,那么将发生一个ASSERT_FAILURE异常(如果在计算condition时发生错误,它会被报告为一个普通错误)。
如果提供了可选的message,它是一个结果(如果非空)被用来替换默认错误消息文本“assertion failed”的表达式(如果condition失败)。message表达式在断言成功的普通情况下不会被计算。
通过配置参数plsql.check_asserts可以启用或者禁用断言测试,这个参数接受布尔值且默认为on。如果这个参数为off,则ASSERT语句什么也不做。
注意ASSERT是为了检测程序的bug,而不是报告普通的错误情况。如果要报告普通错误,请使用前面介绍的RAISE语句。
10.触发器函数
PL/SQL可以被用来在数据更改或者数据库事件上定义触发器函数。触发器函数用CREATE FUNCTION命令创建,它被声明为一个没有参数并且返回类型为trigger(对于数据更改触发器)或者event_trigger(对于数据库事件触发器)的函数。名为UX_something的特殊局部变量将被自动创建用以描述触发该调用的条件。
10.1.数据改变的触发器
一个数据更改触发器被声明为一个没有参数并且返回类型为trigger的函数。注意,如下所述,即便该函数准备接收一些在CREATE TRIGGER中指定的参数 — 这类参数通过TG_ARGV传递,也必须把它声明为没有参数。
当一个PL/SQL函数当做触发器调用时,在顶层块会自动创建一些特殊变量。如下所示。
-
NEW
数据类型是
RECORD;该变量为行级触发器中的INSERT/UPDATE操作保持新数据行。在语句级别的触发器以及DELETE操作,这个变量是null。 -
OLD
数据类型是
RECORD;该变量为行级触发器中的UPDATE/DELETE操作保持新数据行。在语句级别的触发器以及INSERT操作,这个变量是null。 -
TG_NAME
数据类型是name;该变量包含实际触发的触发器名。
-
TG_WHEN
数据类型是text;是值为
BEFORE、AFTER或INSTEAD OF的一个字符串,取决于触发器的定义。 -
TG_LEVEL
数据类型是text;是值为
ROW或STATEMENT的一个字符串,取决于触发器的定义。 -
TG_OP
数据类型是text;是值为
INSERT、UPDATE、DELETE或TRUNCATE的一个字符串,它说明触发器是为哪个操作引发。 -
TG_RELID
数据类型是oid;是导致触发器调用的表的对象 ID。
-
TG_RELNAME
数据类型是name;是导致触发器调用的表的名称。现在已经被废弃,并且可能在未来的一个发行中消失。使用
TG_TABLE_NAME替代。 -
TG_TABLE_NAME
数据类型是name;是导致触发器调用的表的名称。
-
TG_TABLE_SCHEMA
数据类型是name;是导致触发器调用的表所在的模式名。
-
TG_NARGS
数据类型是integer;在
CREATE TRIGGER语句中给触发器函数的参数数量。 -
TG_ARGV[]
数据类型是text数组;来自
CREATE TRIGGER语句的参数。索引从 0 开始记数。非法索引(小于 0 或者大于等于tg_nargs)会导致返回一个空值。 -
INSERTING
数据类型是bool;是判断当前操作是否是
insert操作,如果是返回true;否则返回false。可以在if、case...when、when之后使用。 -
UPDATING
数据类型是bool;是判断当前操作是否是
update操作,如果是返回true;否则返回false。可以在if、case...when、when之后使用。 -
DELETING
数据类型是bool;是判断当前操作是否是
delete操作,如果是返回true;否则返回false。可以在if、case...when、when之后使用。
当一个PL/SQL函数当做触发器调用时,在顶层块会自动创建一些特殊函数。如下所示。
-
updating()
返回值是bool;其参数为触发器所在表的列名。作用是判断当前操作是否是
update,并修改了与参数同名的列。如果修改返回true;否则返回false。可以在if、case...when、when之后使用。如updating('name'),判断当前操作是否是
update,并修改了name列。
一个触发器函数必须返回NULL或者是一个与触发器为之引发的表结构完全相同的记录/行值。
BEFORE引发的行级触发器可以返回一个空来告诉触发器管理器跳过对该行剩下的操作(即后续的触发器将不再被引发,并且不会对该行发生INSERT/UPDATE/DELETE)。如果返回了一个非空值,那么对该行值会继续操作。返回不同于原始NEW的行值将修改将要被插入或更新的行。因此,如果该触发器函数想要触发动作正常成功而不修改行值,NEW(或者另一个相等的值)必须被返回。要修改将被存储的行,可以直接在NEW中替换单一值并且返回修改后的NEW,或者构建一个全新的记录/行来返回。在一个DELETE上的前触发器情况下,返回值没有直接效果,但是它必须为非空以允许触发器动作继续下去。注意NEW在DELETE触发器中是空值,因此返回它通常没有意义。在DELETE中的常用方法是返回OLD。
INSTEAD OF触发器(总是行级触发器,并且可能只被用于视图)能够返回空来表示它们没有执行任何更新,并且对该行剩余的操作可以被跳过(即后续的触发器不会被引发,并且该行不会被计入外围INSERT/UPDATE/DELETE的行影响状态中)。否则一个非空值应该被返回用以表示该触发器执行了所请求的操作。对于INSERT和UPDATE操作,返回值应该是NEW,触发器函数可能对它进行了修改来支持INSERT RETURNING和UPDATE RETURNING(这也将影响被传递给任何后续触发器的行值,或者被传递给带有ON CONFLICT DO UPDATE的INSERT语句中一个特殊的EXCLUDED别名引用)。对于DELETE操作,返回值应该是OLD。
一个AFTER行级触发器或一个BEFORE或AFTER语句级触发器的返回值总是会被忽略,它可能也是空。不过,任何这些类型的触发器可能仍会通过抛出一个错误来中止整个操作。
例 一个 PL/SQL 触发器函数展示了PL/SQL中一个触发器函数的示例。
例 一个 PL/SQL 触发器函数
这个示例触发器保证:任何时候一个行在表中被插入或更新时,当前用户名和时间也会被标记在该行中。并且它会检查给出了一个雇员的姓名以及薪水是一个正值。
CREATE TABLE emp (
empname text,
salary integer,
last_date timestamp,
last_user text
);
CREATE FUNCTION emp_stamp() RETURNS trigger AS $emp_stamp$
BEGIN
-- 检查给出了 empname 以及 salary
IF NEW.empname IS NULL THEN
RAISE EXCEPTION 'empname cannot be null';
END IF;
IF NEW.salary IS NULL THEN
RAISE EXCEPTION '% cannot have null salary', NEW.empname;
END IF;
-- 谁会倒贴钱为了工作?
IF NEW.salary < 0 THEN
RAISE EXCEPTION '% cannot have a negative salary', NEW.empname;
END IF;
-- 记住谁在什么时候改变了工资单
NEW.last_date := current_timestamp;
NEW.last_user := current_user;
RETURN NEW;
END;
$emp_stamp$ LANGUAGE plsql;
CREATE TRIGGER emp_stamp BEFORE INSERT OR UPDATE ON emp
FOR EACH ROW EXECUTE FUNCTION emp_stamp();
另一种记录对表的改变的方法涉及到创建一个新表来为每一个发生的插入、更新或删除保持一行。这种方法可以被认为是对一个表的改变的审计。例 一个用于审计的 PL/SQL 触发器函数展示了PL/SQL中一个审计触发器函数的示例。
例 一个用于审计的 PL/SQL 触发器函数
这个示例触发器保证了在emp表上的任何插入、更新或删除一行的动作都被记录(即审计)在emp_audit表中。当前时间和用户名会被记录到行中,还有在其上执行的操作类型。
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- 在 emp_audit 中创建一行来反映 emp 上执行的动作,
-- 使用特殊变量 TG_OP 来得到操作。
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit SELECT 'D', now(), user, OLD.*;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit SELECT 'U', now(), user, NEW.*;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit SELECT 'I', now(), user, NEW.*;
END IF;
RETURN NULL; -- 因为这是一个 AFTER 触发器,结果被忽略
END;
$emp_audit$ LANGUAGE plsql;
CREATE TRIGGER emp_audit
AFTER INSERT OR UPDATE OR DELETE ON emp
FOR EACH ROW EXECUTE FUNCTION process_emp_audit();
前一个示例的一种变体使用一个视图将主表连接到审计表来展示每一项最后被修改是什么时间。这种方法还是记录了对于表修改的完整审查跟踪,但是也提供了审查跟踪的一个简化视图,只为每一个项显示从审查跟踪生成的最后修改时间戳。例 一个用于审计的 PL/SQL 视图触发器函数展示了在PL/SQL中一个视图上审计触发器的示例。
例 一个用于审计的 PL/SQL 视图触发器函数
这个示例在视图上使用了一个触发器让它变得可更新,并且确保视图中一行的任何插入、更新或删除被记录(即审计)在emp_audit表中。当前时间和用户名会被与执行的操作类型一起记录,并且该视图会显示每一行的最后修改时间。
CREATE TABLE emp (
empname text PRIMARY KEY,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer,
stamp timestamp NOT NULL
);
CREATE VIEW emp_view AS
SELECT e.empname,
e.salary,
max(ea.stamp) AS last_updated
FROM emp e
LEFT JOIN emp_audit ea ON ea.empname = e.empname
GROUP BY 1, 2;
CREATE OR REPLACE FUNCTION update_emp_view() RETURNS TRIGGER AS $$
BEGIN
--
-- 执行 emp 上所要求的操作,并且在 emp_audit 中创建一行来反映对 emp 的改变。
--
IF (TG_OP = 'DELETE') THEN
DELETE FROM emp WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
OLD.last_updated = now();
INSERT INTO emp_audit VALUES('D', user, OLD.*);
RETURN OLD;
ELSIF (TG_OP = 'UPDATE') THEN
UPDATE emp SET salary = NEW.salary WHERE empname = OLD.empname;
IF NOT FOUND THEN RETURN NULL; END IF;
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('U', user, NEW.*);
RETURN NEW;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp VALUES(NEW.empname, NEW.salary);
NEW.last_updated = now();
INSERT INTO emp_audit VALUES('I', user, NEW.*);
RETURN NEW;
END IF;
END;
$$ LANGUAGE plsql;
CREATE TRIGGER emp_audit
INSTEAD OF INSERT OR UPDATE OR DELETE ON emp_view
FOR EACH ROW EXECUTE FUNCTION update_emp_view();
触发器的一种用法是维护一个表的另一个汇总表。作为结果的汇总表可以用来在特定查询中替代原始表 — 通常会大量减少运行时间。这种技术常用于数据仓库中,在其中被度量或被观察数据的表(称为事实表)可能会极度大。例 一个 PL/SQL 用于维护汇总表的触发器函数展示了PL/SQL中一个为数据仓库事实表维护汇总表的触发器函数的示例。
例 一个 PL/SQL 用于维护汇总表的触发器函数
这里详述的模式有一部分是基于 Ralph Kimball 所作的The Data Warehouse Toolkit中的Grocery Store示例。
--
-- 主表 - 时间维度和销售事实。
--
CREATE TABLE time_dimension (
time_key integer NOT NULL,
day_of_week integer NOT NULL,
day_of_month integer NOT NULL,
month integer NOT NULL,
quarter integer NOT NULL,
year integer NOT NULL
);
CREATE UNIQUE INDEX time_dimension_key ON time_dimension(time_key);
CREATE TABLE sales_fact (
time_key integer NOT NULL,
product_key integer NOT NULL,
store_key integer NOT NULL,
amount_sold numeric(12,2) NOT NULL,
units_sold integer NOT NULL,
amount_cost numeric(12,2) NOT NULL
);
CREATE INDEX sales_fact_time ON sales_fact(time_key);
--
-- 汇总表 - 按时间汇总销售
--
CREATE TABLE sales_summary_bytime (
time_key integer NOT NULL,
amount_sold numeric(15,2) NOT NULL,
units_sold numeric(12) NOT NULL,
amount_cost numeric(15,2) NOT NULL
);
CREATE UNIQUE INDEX sales_summary_bytime_key ON sales_summary_bytime(time_key);
--
-- 在 UPDATE、INSERT、DELETE 时修改汇总列的函数和触发器。
--
CREATE OR REPLACE FUNCTION maint_sales_summary_bytime() RETURNS TRIGGER
AS $maint_sales_summary_bytime$
DECLARE
delta_time_key integer;
delta_amount_sold numeric(15,2);
delta_units_sold numeric(12);
delta_amount_cost numeric(15,2);
BEGIN
-- 算出增量/减量数。
IF (TG_OP = 'DELETE') THEN
delta_time_key = OLD.time_key;
delta_amount_sold = -1 * OLD.amount_sold;
delta_units_sold = -1 * OLD.units_sold;
delta_amount_cost = -1 * OLD.amount_cost;
ELSIF (TG_OP = 'UPDATE') THEN
-- 禁止更改 the time_key 的更新-
-- (可能不会太麻烦,因为大部分的更改是用 DELETE + INSERT 完成的)。
IF ( OLD.time_key != NEW.time_key) THEN
RAISE EXCEPTION 'Update of time_key : % -> % not allowed',
OLD.time_key, NEW.time_key;
END IF;
delta_time_key = OLD.time_key;
delta_amount_sold = NEW.amount_sold - OLD.amount_sold;
delta_units_sold = NEW.units_sold - OLD.units_sold;
delta_amount_cost = NEW.amount_cost - OLD.amount_cost;
ELSIF (TG_OP = 'INSERT') THEN
delta_time_key = NEW.time_key;
delta_amount_sold = NEW.amount_sold;
delta_units_sold = NEW.units_sold;
delta_amount_cost = NEW.amount_cost;
END IF;
-- 插入或更新带有新值的汇总行。
<<insert_update>>
LOOP
UPDATE sales_summary_bytime
SET amount_sold = amount_sold + delta_amount_sold,
units_sold = units_sold + delta_units_sold,
amount_cost = amount_cost + delta_amount_cost
WHERE time_key = delta_time_key;
EXIT insert_update WHEN found;
BEGIN
INSERT INTO sales_summary_bytime (
time_key,
amount_sold,
units_sold,
amount_cost)
VALUES (
delta_time_key,
delta_amount_sold,
delta_units_sold,
delta_amount_cost
);
EXIT insert_update;
EXCEPTION
WHEN UNIQUE_VIOLATION THEN
-- 什么也不做
END;
END LOOP insert_update;
RETURN NULL;
END;
$maint_sales_summary_bytime$ LANGUAGE plsql;
CREATE TRIGGER maint_sales_summary_bytime
AFTER INSERT OR UPDATE OR DELETE ON sales_fact
FOR EACH ROW EXECUTE FUNCTION maint_sales_summary_bytime();
INSERT INTO sales_fact VALUES(1,1,1,10,3,15);
INSERT INTO sales_fact VALUES(1,2,1,20,5,35);
INSERT INTO sales_fact VALUES(2,2,1,40,15,135);
INSERT INTO sales_fact VALUES(2,3,1,10,1,13);
SELECT * FROM sales_summary_bytime;
DELETE FROM sales_fact WHERE product_key = 1;
SELECT * FROM sales_summary_bytime;
UPDATE sales_fact SET units_sold = units_sold * 2;
SELECT * FROM sales_summary_bytime;
AFTER也可以利用传递表来观察被触发语句更改的整个行集合。CREATE TRIGGER命令会为一个或者两个传递表分配名字,然后函数可以引用那些名字,就好像它们是只读的临时表一样。例 用传递表进行审计展示了一个示例。
例 用传递表进行审计
这个示例产生和例 一个用于审计的 PL/SQL 触发器函数相同的结果,但并未使用一个为每一行都触发的触发器,而是在把相关信息收集到一个传递表中之后用了一个只为每个语句引发一次的触发器。当调用语句修改了很多行时,这种方法明显比行触发器方法快。注意必须为每一种事件建立一个单独的触发器声明,因为每种情况的REFERENCING子句必须不同。但是这并不能阻止使用单一的触发器函数(实际上,使用三个单独的函数会更好,因为可以避免在TG_OP上的运行时测试)。
CREATE TABLE emp (
empname text NOT NULL,
salary integer
);
CREATE TABLE emp_audit(
operation char(1) NOT NULL,
stamp timestamp NOT NULL,
userid text NOT NULL,
empname text NOT NULL,
salary integer
);
CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
BEGIN
--
-- 在emp_audit中创建行来反映在emp上执行的操作,
-- 利用特殊变量TG_OP来区分操作。
--
IF (TG_OP = 'DELETE') THEN
INSERT INTO emp_audit
SELECT 'D', now(), user, o.* FROM old_table o;
ELSIF (TG_OP = 'UPDATE') THEN
INSERT INTO emp_audit
SELECT 'U', now(), user, n.* FROM new_table n;
ELSIF (TG_OP = 'INSERT') THEN
INSERT INTO emp_audit
SELECT 'I', now(), user, n.* FROM new_table n;
END IF;
RETURN NULL; -- 由于这是一个AFTER触发器,所以结果被忽略
END;
$emp_audit$ LANGUAGE plsql;
CREATE TRIGGER emp_audit_ins
AFTER INSERT ON emp
REFERENCING NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_upd
AFTER UPDATE ON emp
REFERENCING OLD TABLE AS old_table NEW TABLE AS new_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
CREATE TRIGGER emp_audit_del
AFTER DELETE ON emp
REFERENCING OLD TABLE AS old_table
FOR EACH STATEMENT EXECUTE FUNCTION process_emp_audit();
10.2.事件触发器
PL/SQL可以被用来定义事件触发器。UXDB要求一个可以作为事件触发器调用的函数必须被声明为没有参数并且返回类型为event_trigger。
当一个PL/SQL函数被作为一个事件触发器调用,在顶层块中会自动创建一些特殊变量。如下所示。
-
TG_EVENT数据类型是text;它是一个表示引发触发器的事件的字符串。
-
TG_TAG数据类型是text;它是一个变量,包含了该触发器为之引发的命令标签。
例 一个 PL/SQL 事件触发器函数展示了PL/SQL中一个事件触发器函数的示例。
例 一个 PL/SQL 事件触发器函数
这个示例触发器在受支持命令每一次被执行时会简单地抛出一个NOTICE消息。
CREATE OR REPLACE FUNCTION snitch() RETURNS event_trigger AS $$
BEGIN
RAISE NOTICE 'snitch: % %', tg_event, tg_tag;
END;
$$ LANGUAGE plsql;
CREATE EVENT TRIGGER snitch ON ddl_command_start EXECUTE FUNCTION snitch();
11.PL/SQL的内部
这一节讨论了一些PL/SQL用户应该知道的一些重要的实现细节。
11.1.变量替换
一个PL/SQL函数中的 SQL 语句和表达式能够引用该函数的变量和参数。在现象背后,PL/SQL会为这些引用替换查询参数。只有在语法上允许一个参数或列引用的地方才会替换参数。作为一种极端情况,一般不建议使用如下示例。
INSERT INTO foo (foo) VALUES (foo);
foo的第一次出现在语法上必须是一个表名, 因此它将不会被替换,即使该函数有一个名为foo的变量。第二次出现必须是该表的一列的名称,因此它也将不会被替换。只有第三次出现是对该函数变量引用的候选。
因为变量名在语法上与表列的名字没什么区别,在也引用表的语句中会有歧义:一个给定的名字意味着一个表列或一个变量?把前一个示例进行修改,如下所示。
INSERT INTO dest (col) SELECT foo + bar FROM src;
这里,dest和src必须是表名,并且col必须是dest的一列,但是foo和bar可能该函数的变量或者src的列。
默认情况下,如果一个 SQL 语句中的名称可能引用一个变量或者一个表列,PL/SQL将报告一个错误。修复这种问题的方法很多:可以重命名变量或列来,或者对有歧义的引用加以限定,或者告诉PL/SQL要引用哪种解释。
最简单的解决方案是重命名变量或列。一种常用的编码规则是为PL/SQL变量使用一种不同于列名的命名习惯。例如,如果将函数变量统一地命名为v_something,而列名不会开始于v_,就不会发生冲突。
另外可以限定有歧义的引用让它们变清晰。在上面的示例中,src.foo将是对表列的一种无歧义的引用。要创建对一个变量的无歧义引用,在一个被标记的块中声明它并且使用块的标签(见PL/SQL的结构)。如下所示。
<<block>>
DECLARE
foo int;
BEGIN
foo := ...;
INSERT INTO dest (col) SELECT block.foo + bar FROM src;
这里block.foo表示变量,即使在src中有一个列foo。函数参数以及诸如FOUND的特殊变量,都能通过函数的名称被限定,因为它们被隐式地声明在一个带有该函数名称的外层块中。
有时候在一个大型的PL/SQL代码体中修复所有的有歧义引用是不现实的。在这种情况下,可以指定PL/SQL应该将有歧义的引用作为变量或表列(这与某些其他系统兼容,例如Oracle)解决。
要在系统范围内改变这种行为,将配置参数plsql.variable_conflict设置为error、use_variable或者use_column(这里error是出厂设置)之一。这个参数会影响PL/SQL函数中语句的后续编译,但是不会影响在当前会话中已经编译过的语句。因为改变这个设置能够导致PL/SQL函数中行为的意想不到的改变,所以只能由一个超级用户来更改它。
可以对逐个函数设置该行为,做法是在函数文本的开始插入这些特殊命令之一,如下所示。
#variable_conflict error
#variable_conflict use_variable
#variable_conflict use_column
这些命令只影响它们所属的函数,并且会覆盖plsql.variable_conflict的设置。如下所示。
CREATE FUNCTION stamp_user(id int, comment text) RETURNS void AS $$
#variable_conflict use_variable
DECLARE
curtime timestamp := now();
BEGIN
UPDATE users SET last_modified = curtime, comment = comment
WHERE users.id = id;
END;
$$ LANGUAGE plsql;
在UPDATE命令中,curtime、comment以及id将引用该函数的变量和参数,不管users有没有这些名称的列。注意,不得不在WHERE子句中对users.id的引用加以限定,以便让它引用表列。但是不需要在UPDATE列表中把对comment的引用限定为一个目标,因为语法上那必须是users的一列。可以用下面的方式写一个相同的不依赖于variable_conflict设置的函数,如下所示。
CREATE FUNCTION stamp_user(id int, comment text) RETURNS void AS $$
<<fn>>
DECLARE
curtime timestamp := now();
BEGIN
UPDATE users SET last_modified = fn.curtime, comment = stamp_user.comment
WHERE users.id = stamp_user.id;
END;
$$ LANGUAGE plsql;
被交给EXECUTE或其变体的命令字符串中不会发生变量替换。如果需要插入一个变化值到这样一个命令中,在构建该字符串值时就这样做,或者使用USING,如执行动态命令中所阐明的。
当前变量替换只能在SELECT、INSERT、UPDATE和DELETE命令中工作,因为主 SQL 引擎只允许查询参数在这些命令中。要在其他语句类型(通常被称为实用语句)中使用一个非常量名称或值,必须将实用语句构建为一个字符串并且EXECUTE它。
11.2.计划缓存
在函数被第一次调用时(在每个会话中),PL/SQL解释器解析函数的源文本并且产生一个内部的二进制指令树。该指令树完全翻译了PL/SQL语句结构,但是该函数中使用的SQL表达式以及SQL命令并没有被立即翻译。
作为该函数中每一个表达式和第一次被执行的SQL命令,PL/SQL解释器使用SPI管理器的SPI_prepare函数解析并且分析该命令来创建一个预备语句。对于那个表达式或命令的后续访问将会重用该预备语句。因此,一个带有很少被访问的条件性代码路径的函数将永远不会发生分析那些在当前会话中永远不被执行的命令的开销。一个缺点是在一个特定表达式或命令中的错误将不能被检测到,直到函数的该部分在执行时被到达(不重要的语法错误在初始的解析中就会被检测到,但是任何更深层次的东西将只有在执行时才能检测到)。
PL/SQL(或者更准确地说是 SPI 管理器)能进一步尝试缓冲与任何特定预备语句相关的执行计划。如果没有使用一个已缓存的计划,那么每次访问该语句时都会生成一个新的执行计划,并且当前的参数值(也就是PL/SQL的变量值)可以被用来优化被选中的计划。如果该语句没有参数,或者要被执行很多次,SPI 管理器将考虑创建一个不依赖特定参数值的一般计划并且将其缓存用于重用。通常只有在执行计划对其中引用的PL/SQL变量值不那么敏感时,才会这样做。如果这样做,每一次生成的计划就是纯利。关于预备语句的行为请详见《优炫数据库管理系统SQL命令手册》中的PREPARE。
由于PL/SQL保存预备语句并且有时候以这种方式保存执行计划,直接出现在一个PL/SQL函数中的 SQL 命令必须在每次执行时引用相同的表和列。也就是说,不能在一个 SQL 命令中把一个参数用作表或列的名字。要绕过这种限制,可以构建PL/SQL EXECUTE使用的动态命令,但是会付出在每次执行时需要执行新解析分析以及构建新执行计划的代价。
记录变量的易变天性在这个关系中带来了另一个问题。当一个记录变量的域被用在表达式或语句中时,域的数据类型不能在该函数的调用之间改变,因为每一个表达式被分析时都将使用第一次到达该表达式时存在的数据类型。必要时,可以用EXECUTE来绕过这个问题。
如果同一个函数被用作一个服务于多个表的触发器,PL/SQL会为每一个这样的表独立地准备并缓存语句 — 也就是对每一种触发器函数和表的组合都会有一个缓存,而不是每个函数一个缓存。这减轻了数据类型变化带来的问题。例如,一个触发器函数将能够成功地使用一个名为key的列工作,即使该列正好在不同的表中有不同的类型。
同样,具有多态参数类型的函数也会为它们已经被调用的每一种实参类型组合都保留一个独立的缓存,这样数据类型差异不会导致意想不到的失败。
语句缓存有时可能在解释时间敏感的值时产生意外的效果。例如这两个函数做的事情就有区别,如下所示。
-
在logfunc1中,UXDB的主解析器在分析
INSERT时就知道字符串'now'应该被解释为timestamp,因为logtable的目标列是这种类型。因此,在INSERT被分析时'now'将被转换为一个timestamp常量,并且在该会话的生命周期内被用于所有对logfunc1的调用。一般不建议这样使用,建议使用now()或current_timestamp函数。CREATE FUNCTION logfunc1(logtxt text) RETURNS void AS $$ BEGIN INSERT INTO logtable VALUES (logtxt, 'now'); END; $$ LANGUAGE plsql; -
在logfunc2中,UXDB的主解析器不知道'now'应该变成什么类型并且因此返回一个text类型的包含字符串now的数据值。在确定对本地变量
curtime的赋值期间,PL/SQL解释器通过调用用于转换的text_out以及timestamp_in函数将这个字符串造型为timestamp类型。因此,计算出来的时间戳会按照程序员的期待在每次执行时更新。虽然这正好符合预期,但是它的效率很差,因此使用now()函数仍然是一种更好的方案。CREATE FUNCTION logfunc2(logtxt text) RETURNS void AS $$ DECLARE curtime timestamp; BEGIN curtime := 'now'; INSERT INTO logtable VALUES (logtxt, curtime); END; $$ LANGUAGE plsql;
12.PL/SQL开发提示
在PL/SQL中进行开发的一种好方法是使用自己选择的文本编辑器来创建函数,并且在另一个窗口中使用uxsql来载入并且测试那些函数。如果正在这样做,使用CREATE OR REPLACE FUNCTION来编写函数是一个好主意。用那种方式只需要重载该文件来更新函数的定义。如下所示。
CREATE OR REPLACE FUNCTION testfunc(integer) RETURNS integer AS $$
....
$$ LANGUAGE plsql;
在运行uxsql期间,可以用下面的命令载入或者重载这样一个函数定义文件。
\i filename.sql
并且接着立即发出 SQL 命令来测试该函数。
另一种在PL/SQL中开发的方式是用一个GUI数据库访问工具,它能方便对过程语言的开发。这种工具的一个示例是uxdbAdmin。这些工具通常提供方便的特性,例如转义单引号以及便于重新创建和调试函数。
12.1.处理引号
一个PL/SQL函数的代码在一个CREATE FUNCTION中被指定为一个字符串。如果用通常的方式把该字符串写在单引号中间,那么该函数体中的任何单引号都必须被双写;同样任何反斜线也必须被双写(假定使用了转义字符串语法)。双写引号最多有点冗长,并且在更复杂的情况中代码会变得完全无法理解,因为很容易发现需要半打或者更多相邻的引号。推荐把函数体写成一个“美元引用”的字符串。在美元引用方法中,从不需要双写任何引号。但是要注意为需要的每一层嵌套选择一个不同的美元引用定界符。例如,CREATE FUNCTION命令如下所示。
CREATE OR REPLACE FUNCTION testfunc(integer) RETURNS integer AS $PROC$
....
$PROC$ LANGUAGE plsql;
在这里面,可以在SQL命令中为简单字符串使用引号并且用$$来界定被组装成字符串的SQL命令片段。如果需要引用包括$$的文本,可以使用$Q$等等。
下列图表展示了在写没有美元引用的引号时需要做什么。在将之前用美元引用的代码翻译成更容易理解的代码时,它们会有所帮助。
-
1 个引号
用来开始和结束函数体,如下所示。
CREATE FUNCTION foo() RETURNS integer AS ' .... ' LANGUAGE plsql;在一个单引号引用的函数体中的任何位置,引号必须成对出现。
-
2 个引号
用于函数体内的字符串,如下所示。
a_output := ''Blah''; SELECT * FROM users WHERE f_name=''foobar'';在美元引用方法中,如下所示。
a_output := 'Blah'; SELECT * FROM users WHERE f_name='foobar';这恰好就是PL/SQL在两种情况中会看到的。
-
4 个引号
当函数内的一个字符串常量中需要一个单引号时,如下所示。
a_output := a_output || '' AND name LIKE ''''foobar'''' AND xyz''实际会被追加到a_output的值将是:
AND name LIKE 'foobar' AND xyz。使用美元引用方法,要注意在这周围的任何美元引用定界符不只是
$$,如下所示。a_output := a_output || $$ AND name LIKE 'foobar' AND xyz$$ -
6 个引号
当在函数体内的一个字符串中的一个单引号与该字符串常量末尾相邻,如下所示。
a_output := a_output || '' AND name LIKE ''''foobar''''''被追加到a_output的值则将是:
AND name LIKE 'foobar'。在美元引用方法中,进行如下使用。
a_output := a_output || $$ AND name LIKE 'foobar'$$ -
10 个引号
当在一个字符串常量(占 8 个引号)中有两个单引号时并且这会挨着该字符串常量的末尾(另外 2 个)。如果正在写一个产生其他函数的函数(如例 从PL/SQL移植一个创建另一个函数的函数到PL/SQL),将很可能只需要这种。如下所示。
a_output := a_output || '' if v_'' || referrer_keys.kind || '' like '''''''''' || referrer_keys.key_string || '''''''''' then return '''''' || referrer_keys.referrer_type || ''''''; end if;'';a_output的值将是下面内容。
if v_... like ''...'' then return ''...''; end if;在美元引用方法中,进行如下使用。
a_output := a_output || $$ if v_$$ || referrer_keys.kind || $$ like '$$ || referrer_keys.key_string || $$' then return '$$ || referrer_keys.referrer_type || $$'; end if;$$;这里假定只需要把单引号放在a_output中,因为在使用前它将被再引用。
12.2.额外的编译时和运行时检查
为了辅助用户在一些简单但常见的问题产生危害之前找到它们,PL/SQL提供了额外的检查。当被启用时,根据配置,它们可以在一个函数的编译期间被用来发出WARNING或者ERROR。一个已经收到了WARNING的函数可以被继续执行而不会产生进一步的消息,因此建议在一个单独的开发环境中进行测试。
根据需要设置plsql.extra_warnings或plsql.extra_errors,适当情况下,在开发和/或测试环境中可以设置为 "all"。
这些附加检查通过配置变量启用,plsql.extra_warnings用于警告,plsql.extra_errors用于错误。两者都可以设置为逗号分隔的检查列表,"none" 或 "all"。默认值为"none"。当前可用的检查列表如下所示。
-
shadowed_variables检查声明是否遮盖了以前定义的变量。
-
strict_multi_assignment某些PL/SQL命令允许一次将值分配给多个变量,例如
SELECT INTO。通常,目标变量的数量和源变量的数量应匹配,尽管PL/SQL将使用NULL来处理缺失的值和被忽略的额外变量。启用此检查将导致 PL/SQL在目标变量数和源变量数不同时引发WARNING或ERROR。 -
too_many_rows启用此检查将导致PL/SQL检查在使用
INTO子句时给定查询是否返回多行。由于INTO语句只会使用一行,让查询返回多行通常会效率低下和/或不确定性,因此很可能会出现错误。
下面的示例显示了plsql.extra_warnings 设置为shadowed_variables的效果。
SET plsql.extra_warnings TO 'shadowed_variables';
CREATE FUNCTION foo(f1 int) RETURNS int AS $$
DECLARE
f1 int;
BEGIN
RETURN f1;
END
$$ LANGUAGE plsql;
WARNING: variable "f1" shadows a previously defined variable
LINE 3: f1 int;
^
CREATE FUNCTION
下面的示例显示了将plsql.extra_warnings 设置为strict_multi_assignment:
SET plsql.extra_warnings TO 'strict_multi_assignment';
CREATE OR REPLACE FUNCTION public.foo()
RETURNS void
LANGUAGE plsql
AS $$
DECLARE
x int;
y int;
BEGIN
SELECT 1 INTO x, y;
SELECT 1, 2 INTO x, y;
SELECT 1, 2, 3 INTO x, y;
END;
$$;
SELECT foo();
WARNING: number of source and target fields in assignment does not match
DETAIL: strict_multi_assignment check of extra_warnings is active.
HINT: Make sure the query returns the exact list of columns.
WARNING: number of source and target fields in assignment does not match
DETAIL: strict_multi_assignment check of extra_warnings is active.
HINT: Make sure the query returns the exact list of columns.
foo
-----
(1 row)
13.从Oracle PL/SQL 移植
这一节解释了UXDB的PL/SQL语言和 Oracle 的PL/SQL语言之间的差别,用以帮助那些从Oracle向UXDB移植应用的人。
PL/SQL与 PL/SQL 在许多方面都非常类似。它是一种块结构的、命令式的语言并且所有变量必须先被声明。赋值、循环和条件则很类似。在从PL/SQL向PL/SQL移植时必须遵守一些事情,如下所示。
如果一个 SQL 命令中使用的名字可能是一个表的列名或者是对一个函数中变量的引用,那么PL/SQL会将它当作一个列名。如变量替换中所述,这对应的是PL/SQL的 plsql.variable_conflict = use_column行为(不是默认行为)。通常最好是首先避免这种歧义,但如果不得不移植依赖于该行为的大量代码,那么设置variable_conflict将是最好的方案。
在UXDB中,函数体必须写成字符串文本。因此需要使用美元符引用或者转义函数体中的单引号(见处理引号)。
数据类型名称常常需要翻译。例如,在 Oracle 中字符串值通常被声明为类型varchar2,这并非 SQL 标准类型。在UXDB中则要使用类型varchar或者text来替代。类似地,要把类型number替换成numeric,或者在适当的时候使用某种其他数字数据类型。
应该用模式把函数组织成不同的分组,而不是用包。
因为没有包,所以也没有包级别的变量。可以在临时表里保存会话级别的状态。
带有REVERSE的整数FOR循环的工作方式不同:PL/SQL中是从第二个数向第一个数倒数,而PL/SQL是从第一个数向第二个数倒数,因此在移植时需要交换循环边界。不幸的是这种不兼容性是不太可能改变的(见FOR)。
查询上的FOR循环(不是游标)的工作方式同样不同:目标变量必须已经被声明,而PL/SQL总是会隐式地声明它们。但是这样做的优点是在退出循环后,变量值仍然可以访问。
在使用游标变量方面,存在一些记法差异。
13.1.移植示例
例 从PL/SQL移植一个简单的函数到PL/SQL展示了如何从PL/SQL移植一个简单的函数到PL/SQL中。
例 从PL/SQL移植一个简单的函数到PL/SQL
这里有一个Oracle PL/SQL函数示例,如下所示。
CREATE OR REPLACE FUNCTION cs_fmt_browser_version(v_name varchar2,
v_version varchar2)
RETURN varchar2 IS
BEGIN
IF v_version IS NULL THEN
RETURN v_name;
END IF;
RETURN v_name || '/' || v_version;
END;
/
show errors;
过一遍这个函数并且看看与PL/SQL相比有什么样的不同,如下所示。
-
类型名称varchar2被改成了varchar或者text。在这一节的示例中,将使用varchar,但如果不需要特定的字符串长度限制,text常常是更好的选择。
-
在函数原型中(不是函数体中)的
RETURN关键字在UXDB中变成了RETURNS。还有,IS变成了AS,并且还需要增加一个LANGUAGE子句,因为PL/SQL并非唯一可用的函数语言。 -
在UXDB中,函数体被认为是一个字符串,所以需要使用引号或者美元符号包围它。这代替了Oracle方法中的用于终止的/。
-
在UXDB中没有show errors命令, 并且也不需要这个命令,因为错误是自动报告的。
这个函数被移植到UXDB后,结果如下所示。
CREATE OR REPLACE FUNCTION cs_fmt_browser_version(v_name varchar,
v_version varchar)
RETURNS varchar AS $$
BEGIN
IF v_version IS NULL THEN
RETURN v_name;
END IF;
RETURN v_name || '/' || v_version;
END;
$$ LANGUAGE plsql;
例 从PL/SQL移植一个创建另一个函数的函数到PL/SQL展示了如何移植一个会创建另一个函数的函数,以及如何处理引号问题。
例 从PL/SQL移植一个创建另一个函数的函数到PL/SQL
下面的过程从一个SELECT语句抓取行,并且为了效率而构建一个带有IF语句中结果的大型函数。
Oracle版本如下所示。
CREATE OR REPLACE PROCEDURE cs_update_referrer_type_proc IS
CURSOR referrer_keys IS
SELECT * FROM cs_referrer_keys
ORDER BY try_order;
func_cmd VARCHAR(4000);
BEGIN
func_cmd := 'CREATE OR REPLACE FUNCTION cs_find_referrer_type(v_host IN VARCHAR2,
v_domain IN VARCHAR2, v_url IN VARCHAR2) RETURN VARCHAR2 IS BEGIN';
FOR referrer_key IN referrer_keys LOOP
func_cmd := func_cmd ||
' IF v_' || referrer_key.kind
|| ' LIKE ''' || referrer_key.key_string
|| ''' THEN RETURN ''' || referrer_key.referrer_type
|| '''; END IF;';
END LOOP;
func_cmd := func_cmd || ' RETURN NULL; END;';
EXECUTE IMMEDIATE func_cmd;
END;
/
show errors;
UXDB版本如下所示。
CREATE OR REPLACE PROCEDURE cs_update_referrer_type_proc() RETURNS void AS $func$
DECLARE
referrer_keys CURSOR IS
SELECT * FROM cs_referrer_keys
ORDER BY try_order;
func_body text;
func_cmd text;
BEGIN
func_body := 'BEGIN';
FOR referrer_key IN referrer_keys LOOP
func_body := func_body ||
' IF v_' || referrer_key.kind
|| ' LIKE ' || quote_literal(referrer_key.key_string)
|| ' THEN RETURN ' || quote_literal(referrer_key.referrer_type)
|| '; END IF;' ;
END LOOP;
func_body := func_body || ' RETURN NULL; END;';
func_cmd :=
'CREATE OR REPLACE FUNCTION cs_find_referrer_type(v_host varchar,
v_domain varchar,
v_url varchar)
RETURNS varchar AS '
|| quote_literal(func_body)
|| ' LANGUAGE plsql;' ;
EXECUTE func_cmd;
END;
$func$ LANGUAGE plsql;
请注意函数体是如何被单独构建并且通过quote_literal被传递以双写其中的任何引号。需要这个技术是因为无法安全地使用美元引用定义新函数:不确定从referrer_key.key_string域中来的什么字符串会被插入(这里假定referrer_key.kind可以确信总是为host、domain或者url,但是referrer_key.key_string可能是任何东西,特别是它可能包含美元符号)。这个函数实际上是在Oracle的原版上的改进,因为当referrer_key.key_string或者referrer_key.referrer_type包含引号时,它将不会生成坏掉的代码。
例 从PL/SQL移植一个带有字符串操作以及OUT参数的过程到PL/SQL展示了如何移植一个带有OUT参数和字符串处理的函数。UXDB没有内建的instr函数,但是可以用其它函数的组合来创建一个。在附录中有一个instr的PL/SQL实现,可以用它让移植变得更容易。
例 从PL/SQL移植一个带有字符串操作以及OUT参数的过程到PL/SQL
下面的Oracle PL/SQL 过程被用来解析一个 URL 并且返回一些元素(主机、路径和查询)。
Oracle 版本如下所示。
CREATE OR REPLACE PROCEDURE cs_parse_url(
v_url IN VARCHAR2,
v_host OUT VARCHAR2, -- 这将被传回去
v_path OUT VARCHAR2, -- 这个也是
v_query OUT VARCHAR2) -- 还有这个
IS
a_pos1 INTEGER;
a_pos2 INTEGER;
BEGIN
v_host := NULL;
v_path := NULL;
v_query := NULL;
a_pos1 := instr(v_url, '//');
IF a_pos1 = 0 THEN
RETURN;
END IF;
a_pos2 := instr(v_url, '/', a_pos1 + 2);
IF a_pos2 = 0 THEN
v_host := substr(v_url, a_pos1 + 2);
v_path := '/';
RETURN;
END IF;
v_host := substr(v_url, a_pos1 + 2, a_pos2 - a_pos1 - 2);
a_pos1 := instr(v_url, '?', a_pos2 + 1);
IF a_pos1 = 0 THEN
v_path := substr(v_url, a_pos2);
RETURN;
END IF;
v_path := substr(v_url, a_pos2, a_pos1 - a_pos2);
v_query := substr(v_url, a_pos1 + 1);
END;
/
show errors;
这里是一种到PL/SQL的可能翻译,如下所示。
CREATE OR REPLACE FUNCTION cs_parse_url(
v_url IN VARCHAR,
v_host OUT VARCHAR, -- 这将被传递回去
v_path OUT VARCHAR, -- 这个也是
v_query OUT VARCHAR) -- 以及这个
AS $$
DECLARE
a_pos1 INTEGER;
a_pos2 INTEGER;
BEGIN
v_host := NULL;
v_path := NULL;
v_query := NULL;
a_pos1 := instr(v_url, '//');
IF a_pos1 = 0 THEN
RETURN;
END IF;
a_pos2 := instr(v_url, '/', a_pos1 + 2);
IF a_pos2 = 0 THEN
v_host := substr(v_url, a_pos1 + 2);
v_path := '/';
RETURN;
END IF;
v_host := substr(v_url, a_pos1 + 2, a_pos2 - a_pos1 - 2);
a_pos1 := instr(v_url, '?', a_pos2 + 1);
IF a_pos1 = 0 THEN
v_path := substr(v_url, a_pos2);
RETURN;
END IF;
v_path := substr(v_url, a_pos2, a_pos1 - a_pos2);
v_query := substr(v_url, a_pos1 + 1);
END;
$$ LANGUAGE plsql;
这个函数可以使用如下方式。
SELECT * FROM cs_parse_url('http://foobar.com/query.cgi?baz');
例 从PL/SQL移植一个过程到PL/SQL展示了如何移植一个使用了多种Oracle特性的过程。
例 从PL/SQL移植一个过程到PL/SQL
Oracle 版本如下所示。
CREATE OR REPLACE PROCEDURE cs_create_job(v_job_id IN INTEGER) IS
a_running_job_count INTEGER;
BEGIN
LOCK TABLE cs_jobs IN EXCLUSIVE MODE;
SELECT count(*) INTO a_running_job_count FROM cs_jobs WHERE end_stamp IS NULL;
IF a_running_job_count > 0 THEN
COMMIT; -- 释放锁
raise_application_error(-20000,
'Unable to create a new job: a job is currently running.');
END IF;
DELETE FROM cs_active_job;
INSERT INTO cs_active_job(job_id) VALUES (v_job_id);
BEGIN
INSERT INTO cs_jobs (job_id, start_stamp) VALUES (v_job_id, now());
EXCEPTION
WHEN dup_val_on_index THEN NULL; -- 如果已经存在也不用担心
END;
COMMIT;
END;
/
show errors
如何将这个过程移植到PL/SQL,如下所示。
CREATE OR REPLACE PROCEDURE cs_create_job(v_job_id integer) RETURNS void AS $$
DECLARE
a_running_job_count integer;
BEGIN
LOCK TABLE cs_jobs IN EXCLUSIVE MODE;
SELECT count(*) INTO a_running_job_count FROM cs_jobs WHERE end_stamp IS NULL;
IF a_running_job_count > 0 THEN
COMMIT; -- 释放锁
RAISE EXCEPTION 'Unable to create a new job: a job is currently running'; --1
END IF;
DELETE FROM cs_active_job;
INSERT INTO cs_active_job(job_id) VALUES (v_job_id);
BEGIN
INSERT INTO cs_jobs (job_id, start_stamp) VALUES (v_job_id, now());
EXCEPTION
WHEN unique_violation THEN --2
-- 如果已经存在不要担心
END;
COMMIT;
END;
$$ LANGUAGE plsql;
-
RAISE的语法与Oracle的语句相当不同,尽管基本的形式RAISE exception_name工作起来是相似的。 -
PL/SQL所支持的异常名称不同于Oracle。内建的异常名称集合要更大。目前没有办法声明用户定义的异常名称,尽管能够抛出用户选择的
SQLSTATE值。
13.2.其他要关注的事项
这一节解释了在移植 Oracle PL/SQL函数到UXDB中时要关注的一些其他问题。
13.2.1.异常后隐式回滚
在PL/SQL,当一个异常被EXCEPTION子句捕获之后,从该块的BEGIN以来的所有数据库改变都会被自动回滚。也就是,该行为等效于在Oracle中用下面的代码得到的效果。
BEGIN
SAVEPOINT s1;
... 代码 ...
EXCEPTION
WHEN ... THEN
ROLLBACK TO s1;
... 代码 ...
WHEN ... THEN
ROLLBACK TO s1;
... 代码 ...
END;
如果正在翻译一个使用这种风格的SAVEPOINT以及ROLLBACK TO的 Oracle 过程,只要忽略掉SAVEPOINT以及ROLLBACK TO。如果 Oracle 过程是以不同的方法使用SAVEPOINT以及ROLLBACK TO。
13.2.2.EXECUTE
PL/SQL的EXECUTE与PL/SQL中的工作相似,但是必须要记住按照执行动态命令中所述地使用quote_literal以及quote_ident。EXECUTE 'SELECT * FROM $1';类型的结构将无法可靠地工作除非使用这些函数。
13.2.3.优化 PL/SQL 函数
UXDB提供了两种函数创建修饰符来优化执行:“volatility”(对于给定的相同参数,函数是否总是返回相同的结果)以及“strictness” (如果任何参数为空,函数是否返回空)。
在利用这些优化属性时,CREATE FUNCTION语句如下所示。
CREATE FUNCTION foo(...) RETURNS integer AS $$
...
$$ LANGUAGE plsql STRICT IMMUTABLE;
13.3.附录
这一节包含了一组Oracle兼容的instr函数代码,可以用它来简化移植工作。
--
-- instr 函数模仿 Oracle 的对应函数
-- 语法: instr(string1, string2 [, n [, m]])
-- 其中 [] 表示可选参数。
--
-- 从第n个字符开始搜索string1,要求找到string2的第m次出现。
-- 如果n为负,则从后向前搜索,从string1的末尾开始的第abs(n)个字符开始。
-- 如果没有传n,假定它为1(从第1个字符开始搜索)。
-- 如果没有传m,假定它为1(找第1次出现)。
-- 在string1中返回string2的开始索引,如果没有找到string2则为0。
--
CREATE FUNCTION instr(varchar, varchar) RETURNS integer AS $$
BEGIN
RETURN instr($1, $2, 1);
END;
$$ LANGUAGE plsql STRICT IMMUTABLE;
CREATE FUNCTION instr(string varchar, string_to_search_for varchar,
beg_index integer)
RETURNS integer AS $$
DECLARE
pos integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
length integer;
ss_length integer;
BEGIN
IF beg_index > 0 THEN
temp_str := substring(string FROM beg_index);
pos := position(string_to_search_for IN temp_str);
IF pos = 0 THEN
RETURN 0;
ELSE
RETURN pos + beg_index - 1;
END IF;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search_for);
length := char_length(string);
beg := length + 1 + beg_index;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
IF string_to_search_for = temp_str THEN
RETURN beg;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plsql STRICT IMMUTABLE;
CREATE FUNCTION instr(string varchar, string_to_search_for varchar,
beg_index integer, occur_index integer)
RETURNS integer AS $$
DECLARE
pos integer NOT NULL DEFAULT 0;
occur_number integer NOT NULL DEFAULT 0;
temp_str varchar;
beg integer;
i integer;
length integer;
ss_length integer;
BEGIN
IF occur_index <= 0 THEN
RAISE 'argument ''%'' is out of range', occur_index
USING ERRCODE = '22003';
END IF;
IF beg_index > 0 THEN
beg := beg_index - 1;
FOR i IN 1..occur_index LOOP
temp_str := substring(string FROM beg + 1);
pos := position(string_to_search_for IN temp_str);
IF pos = 0 THEN
RETURN 0;
END IF;
beg := beg + pos;
END LOOP;
RETURN beg;
ELSIF beg_index < 0 THEN
ss_length := char_length(string_to_search_for);
length := char_length(string);
beg := length + 1 + beg_index;
WHILE beg > 0 LOOP
temp_str := substring(string FROM beg FOR ss_length);
IF string_to_search_for = temp_str THEN
occur_number := occur_number + 1;
IF occur_number = occur_index THEN
RETURN beg;
END IF;
END IF;
beg := beg - 1;
END LOOP;
RETURN 0;
ELSE
RETURN 0;
END IF;
END;
$$ LANGUAGE plsql STRICT IMMUTABLE;
14.包
包是由plsql语句实现的逻辑相关的一组函数,过程,变量,类型,异常等对象封装而成的程序库。这个程序库中的对象有两类,一类是可以由包外部的SQL或PLSQL程序访问,称之为公共对象,一类是为了支持公共对象的功能而申明和定义的包内部私有对象。公共对象表明了包的功能,由包接口规范申明。私有对象的申明、定义以及公共对象的定义有包体来实现。
plsql包和其它程序语言的库的特点和功用是完全一致的。对于系统设计模块化,使用接口标准化等有很强的促进作用,可以降低开发和维护成本,提高用户系统稳定性。
14.1.包接口规范
包接口规范申明了包公共对象,包括函数、过程、常量、变量、游标、游标变量、异常的申明,以及公共类型的定义。
-
包接口规范的创建
包是存储在系统表中的对象,由SQL语句
create package创建。创建包支持accessible_by_clause子句,功能是只有子句里定义的白名单可以调用包里的对象,子句为空则不做限制。
CREATE [OR REPLACE] PACKAGE pkg_name [accessible_by_clause] { AS | IS } ( variable_declaration; | constant_declaration; | cursor_declaration; | cursor_var_declaration; | exception_declaration; | type_definition; | function_declaration; | procedure_declaration; ) + END; / accessible_by_clause := ACCESSIBLE BY ( { FUNCTION | PROCEDURE | PACKAGE | TRIGGER | TYPE } [schema.]unit_name [, { FUNCTION | PROCEDURE | PACKAGE | TRIGGER | TYPE } [schema.]unit_name ]... ) -
示例
create or replace package pkg ACCESSIBLE BY (PROCEDURE trustproc) as num number; arr number[]; rec record; FUNCTION sum(a1 integer , a2 integer ) RETURN integer; end; /accessible_by_clause子句示例,如下所示。
-- 创建包 CREATE OR REPLACE PACKAGE protected_pkg2 ACCESSIBLE BY (PROCEDURE top_trusted_proc1 ) AS PROCEDURE public_proc; PROCEDURE private_proc ; END; -- 创建包体 CREATE OR REPLACE PACKAGE BODY protected_pkg2 AS PROCEDURE public_proc AS BEGIN DBMS_OUTPUT.PUT_LINE('++> Executed protected_pkg.public_proc'); END; PROCEDURE private_proc AS BEGIN DBMS_OUTPUT.PUT_LINE('--> Executed protected_pkg.private_proc'); END; END; -- 创建存储过程 CREATE OR REPLACE PROCEDURE top_trusted_proc1 AS BEGIN DBMS_OUTPUT.PUT_LINE('-##-> top_trusted_proc1 calls protected_pkg.private_proc '); protected_pkg2.private_proc; END; CREATE OR REPLACE PROCEDURE top_untrusted_proc2 AS BEGIN DBMS_OUTPUT.PUT_LINE('-##-> top_untrusted_proc2 calls protected_pkg.private_proc '); protected_pkg2.private_proc; END; -- 执行正确(有权限) begin top_trusted_proc1; end; > OK -##-> top_trusted_proc1 calls protected_pkg.private_proc --> Executed protected_pkg.private_proc -- 执行错误(无权限) begin protected_pkg2.private_proc(); end; Err:insufficient privilege to access object PROTECTED_PKG2
14.2.包体
包接口功能是由包体定义的各对象来实现的,包体可以申明和定义所有包接口类型对象,作为私有对象,同时必须对包接口中申明的函数、过程、游标进行定义。包还可以定义一个初始化语句段落,当一个会话第一次访问某个包中的任意对象时,这个初始化语句段落会被系统先执行,通常用来对包的各个变量状态进行赋值,初始化段落执行完之后,系统才会访问包中的目标对象;第二次以及以后对包对象的访问,则无需执行初始化段落。
-
包体的创建
包体由SQL语句
create package body创建。CREATE [OR REPLACE] PACKAGE BODY pkg_name { AS | IS } ( variable_declaration; | constant_declaration; | cursor_declaration; | cursor_var_declaration; | exception_declaration; | type_definition; | function_declaration; | procedure_declaration; | cursor_definition; | function_definition; | procedure_definition;) * [ BEGIN ( plsql_statement; ) + ] END; / -
示例
create or replace package body pkg as FUNCTION sum(a1 integer , a2 integer ) RETURN integer is result integer; BEGIN result := a1 + a2; dbms_output.put_line('arr: ' || arr); RETURN result; END; BEGIN select 1 as one, 2 as two, 'abc' as str into rec; arr := '{1,10,100,1000,1000}'; dbms_output.put_line('in package init'); END; /
14.3.包变量
包中的变量称为包变量(Package Variable),它们是包内的全局变量,可供包中的所有存储过程和函数共享和访问。
-
包变量定义
包变量必须在包接口定义中声明。
-
包变量引用
package_variable ::= [schema_name . ] package_name . variable_name -
包变量读
表达式中,包变量可以在任何相同类型的普通plsql变量合法的语法位置使用。
-
包变量写
-
包变量赋值
package_variable := expression ; -
集合包变量成员赋值
package_variable (index ) := expression ; -
记录类型包变量成员赋值
package_variable . field := expression; -
函数/过程调用的
out或inout类型参数 -
select ... into语句的目标 -
fetch ... into语句的目标 -
execute immediate ... into语句的目标 -
insert/delete/update ... returning into语句的目标 -
execute immediate ... returning into语句的目标 -
select ... bulk collect into语句的目标 -
execute immediate ... bulk collect into语句的目标 -
fetch ... bulk collect into语句的目标
-
14.4.包类型
包类型(type_definition)指的是包中自定义的数据类型。
14.4.1.包接口记录类型
-
定义
包接口记录类型(Record Type)是一种用于包接口中的用户自定义的数据类型,包含多个字段,每个字段可以有不同的数据类型。
-
语法
TYPE record_type IS RECORD ( field_definition [, field_definition]... ) ; -
功能
-
包接口记录类型的定义,示例如下。
CREATE OR REPLACE PACKAGE pkg01_type_record IS -- 定义记录类型 TYPE typ1_rec IS RECORD ( zero INTEGER, one INTEGER, two INTEGER ); END pkg01_type_record ; / -
包接口记录类型的使用,示例如下。
-- 包规范 CREATE OR REPLACE PACKAGE ExamplePackage IS -- 记录类型定义 TYPE EmployeeRecordType IS RECORD ( emp_id NUMBER, emp_name VARCHAR2(100), emp_salary NUMBER ); -- 函数声明,使用记录类型作为参数和返回类型 FUNCTION get_employee_details(emp_id IN NUMBER) RETURN EmployeeRecordType; END ExamplePackage; / -- 包体 CREATE OR REPLACE PACKAGE BODY ExamplePackage IS -- 函数实现,使用包规范中定义的记录类型 FUNCTION get_employee_details(emp_id IN NUMBER) RETURN EmployeeRecordType IS employee_details EmployeeRecordType; BEGIN employee_details.emp_id := emp_id; employee_details.emp_name := 'John Doe'; employee_details.emp_salary := 50000; RETURN employee_details; END ; END ExamplePackage; / --使用 select ExamplePackage.get_employee_details(1); -
匿名块中访问包接口记录类型的字段,示例如下。
CREATE OR REPLACE PACKAGE pkg02_type_record AS -- 定义记录类型 TYPE typ1_rec IS RECORD ( zero INTEGER, one INTEGER, two INTEGER ); END pkg02_type_record; / --在匿名块中使用包接口的记录类型 DO $$ DECLARE v1_rec pkg02_type_record.typ1_rec; BEGIN -- 初始化记录变量 v1_rec.zero := 0; v1_rec.one := 1; v1_rec.two := 2; -- 使用 RAISE NOTICE 输出信息 RAISE NOTICE 'Zero: % , One: % , Two: %', v1_rec.zero, v1_rec.one, v1_rec.two; END; $$ ;
-
14.4.2.包游标变量类型
-
定义
在包内创建的游标变量类型,可在包外使用该类型创建游标变量。
注意事项
在包头和包体中都不支持在包中定义游标变量,否则会报错:“游标变量无法作为包的一部分进行声明”,此时系统表中不会写入,调用也会报错。
-
分类
-
强游标类型
若指定返回值类型(return_type),则该类型创建的游标变量都是强游标变量。使用强游标变量,可以仅关联返回指定类型的查询。
语法
TYPE type IS REF CURSOR [ RETURN {{db_table_or_view|cursor|cursor_variable}%ROWTYPE |record%TYPE |record_type |ref_cursor_type } ]; -
弱游标类型
若没有指定返回值类型(return_type),则SYS_REFCURSOR和该类型创建的游标变量都是弱游标变量。使用弱游标变量,可以关联任何查询。Sys_refcursor是系统预定义的弱游标变量。
语法
TYPE type IS REF CURSOR | SYS_REFCURSOR;
-
-
示例
-- 创建表emp drop table emp; create table emp (empno int, ename varchar(30), deptno int, sal int); insert into emp values(1, 'zs', 101, 1000); insert into emp values(2, 'ls', 102, 2000); insert into emp values(3, 'ww', 103, 3000); insert into emp values(4, 'ws', 104, 4000); insert into emp values(5, 'tim', 105, 5000); insert into emp values(6, 'sd', 101, 1000); insert into emp values(7, 'rb', 101, 4000); insert into emp values(8, 'jsy', 104, 4000); -- 创建表dept drop table dept; create table dept(deptno int, dname varchar(30)); insert into dept values(101, 'room_101'); insert into dept values(102, 'room_102'); insert into dept values(103, 'room_103'); insert into dept values(104, 'room_104'); insert into dept values(105, 'room_105'); SELECT * FROM emp; SELECT * FROM dept; create or replace package pkg01 is type weak_type is ref cursor; type strong_type is ref cursor return emp%rowtype; end; / declare v4 int; v5 emp%rowtype; v6 pkg01.strong_type; -- v6 pkg01.weak_type; begin open v6 for select * from emp; loop fetch v6 into v5; exit when v6%notfound; raise notice'empno : %', v5.empno; end loop; close v6; end; /
14.5.包显式游标变量
-
定义
包显式游标变量用于在包级别处理查询结果集,可在PL/SQL中用于遍历查询的结果。
-
功能
-
包显式游标变量的声明和定义
支持在包规范中声明包显式游标变量,在包体中定义显式游标变量。
注意事项
包中显式游标的状态(例如:cursor_name%found),需要在同一个事务中使用,显式游标的状态才能保存。
声明语法
CURSOR cursor [( cursor_parameter_dec [, cursor_parameter_dec ]... )] RETURN rowtype;定义语法
CURSOR cursor [ ( cursor_parameter_dec [, cursor_parameter_dec ]... )] [ RETURN rowtype] IS select_statement ;支持的rowtype类型:package_name.cursor_name%rowtype。
-
包显式游标变量参数的说明
与匿名块中使用相同。
-
支持用默认值,当使用指定默认值时,open游标时可以不需要指定参数值。
-
游标参数作用域,只在该游标中使用。
-
支持显式游标参数,可以不出现在select语句中。
语法
parameter [IN] datatype [ { := | DEFAULT } expression ] -
-
包显式游标变量返回类型的说明
语法
{ {db_table_or_view | cursor }%ROWTYPE | record%TYPE | record_type }
-
-
示例
-- 创建表emp
drop table emp;
create table emp (empno int, ename varchar(30), deptno int, sal int);
insert into emp values(1, 'zs', 101, 1000);
insert into emp values(2, 'ls', 102, 2000);
insert into emp values(3, 'ww', 103, 3000);
insert into emp values(4, 'ws', 104, 4000);
insert into emp values(5, 'tim', 105, 5000);
insert into emp values(6, 'sd', 101, 1000);
insert into emp values(7, 'rb', 101, 4000);
insert into emp values(8, 'jsy', 104, 4000);
-- 创建表dept
drop table dept;
create table dept(deptno int, dname varchar(30));
insert into dept values(101, 'room_101');
insert into dept values(102, 'room_102');
insert into dept values(103, 'room_103');
insert into dept values(104, 'room_104');
insert into dept values(105, 'room_105');
SELECT * FROM emp;
SELECT * FROM dept;
create or replace package pkg01 is
v1 int;
v2 varchar(30);
v3 emp%rowtype;
cursor c1 return emp%rowtype;
--cursor c1 return emp%rowtype is select * from emp ;
end;
/
create or replace package BODY pkg01 as
cursor c1 return emp%rowtype is select * from emp;
begin
null;
end;
/
declare
v4 int;
v5 emp%rowtype;
begin
open pkg01.c1 ;
loop
fetch pkg01.c1 into v5;
exit when pkg01.c1%notfound;
DBMS_OUTPUT.PUT_LINE('empno : ' || v5.empno);
end loop;
close pkg01.c1 ;
end;
/
begin; --事务开始
begin
-- 第一次游标打开成功
open pkg01.c1;
end;
/
begin
-- 第二次游标打开失败
open pkg01.c1;
end;
/
end; -- 事务结束
begin; --事务开始
begin
-- 第一次游标打开成功
open pkg01.c1;
end;
/
declare
v1 emp%rowtype;
begin
-- 取出第一行数据
fetch pkg01.c1 into v1;
raise info 'v1 : %', v1;
end;
/
declare
v1 emp%rowtype;
begin
-- 取出第二行数据
fetch pkg01.c1 into v1;
raise info 'v1 : %', v1;
end;
/
begin
close pkg01.c1;
end;
/
end; -- 事务结束
15.异常管理
15.1.描述
异常(PL/SQL 运行时错误)可能来自设计错误、编码错误、硬件故障或其他来源。无法预先处理所有可能触发 的异常,但可以编写异常处理程序,让程序在触发异常的情况下继续运行。
任何 PL/SQL 块都可以有一个异常处理部分,它可以处理一个或多个异常,如下所示。
EXCEPTION
WHEN ex_name_1 THEN statements_1
-- Exception handler
WHEN ex_name_2 OR ex_name_3 THEN statements_2 -- Exception handler
WHEN OTHERS THEN statements_3
-- Exception handler
END;
当 PL/SQL 块的可执行部分触发异常时,可执行部分会停止执行并将控制权转移到异常处理部分。如果抛出异常 ex_name_1,则运行语句 statements_1 。如果抛出异常 ex_name_2 或 ex_name_3,则运行语句 statements_2 。如果抛出其他异常,则运行语句 statements_3。
异常处理程序运行后,控制权转移到封闭块的下一条语句。如果没有封闭块,则:
-
如果异常处理程序在子程序中,则将控制权返回给调用者调用之后的语句处。
-
如果异常处理程序位于匿名块中,则控制权转移到主机环境。
如果在没有异常处理程序的 PL/SQL 块中触发异常,则异常会传播。也就是说,异常会在连续的封闭块中向上抛出,直到一个 PL/SQL 块有一个异常处理程序或没有封闭块为止。如果没有 异常处理程序,那么 PL/SQL 会向调用者或主机环境返回一个未处理的异常,这将决定最终的返回结果。
15.2.异常的种类
异常的种类分为:
-
系统预定义异常
系统预定义异常是 PL/SQL 已命名的异常,这些异常都有一个错误代码,且会在系统运行出错时隐式(自动) 触发。
-
用户自定义异常
可以在任何 PL/SQL 匿名块、子程序或包的声明部分中声明自己的异常。例如,可以声明一个名为
invalid_number的异常标记一个无效数字。用户自定义异常必须显式的触发。
对于命名异常,可以编写特定的异常处理程序,而不是使用OTHERS异常处理程序来处理它。特定的异常处理 程序比OTHERS异常处理程序更有效,因为后者必须调用一个函数来确定它正在处理哪个异常。
15.3.预定义异常
针对许多比较常见的异常以及系统运行时会触发的异常,PL/SQL 内部为其预定义了一个名称。例如:除零错误,对应的预定义异常名称为DIVISION_BY_ZERO。当错误发生时,系统隐式(自动)抛出该异常。
UXDB支持的常见的系统ORACLE预定义异常详见下表。
PL/SQL 预定义异常表
| UXDB 异常名 | Oracle 对应异常名 | 异常说明 |
|---|---|---|
| CASE_NOT_FOUND | CASE_NOT_FOUND | CASE 语句中没有任何 WHEN 子句满足条件,且没有 ELSE 子句。 |
| COLLECTION_IS_NULL | COLLECTION_IS_NULL | 调用未初始化的嵌套表或可变数组的方法(不含 EXISTS),或为其元素赋值。 |
| DIVISION_BY_ZERO | ZERO_DIVIDE | 除零错误。 |
| INVALID_TEXT_REPRESENTATION | INVALID_NUMBER | 出现运算、转换、截位或长度的约束错误。 |
| NO_DATA_FOUND | NO_DATA_FOUND | 核心查询或操作未获取到任何数据。 |
| NUMERIC_VALUE_OUT_OF_RANGE | VALUE_ERROR | 数值类型超过预定义的精度或范围。 |
| SUBSCRIPT_BEYOND_COUNT | SUBSCRIPT_BEYOND_COUNT | 调用嵌套表或可变数组时,使用的下标索引超出对应元素的总个数。 |
| SUBSCRIPT_OUTSIDE_LIMIT | SUBSCRIPT_OUTSIDE_LIMIT | 调用嵌套表或可变数组时,下标索引不在合法范围内(如使用负数索引)。 |
| TOO_MANY_ROWS | TOO_MANY_ROWS | SELECT INTO 或子查询返回的结果行数超过一行。 |
| UNIQUE_VIOLATION | DUP_VAL_ON_INDEX | 尝试向具有唯一约束(Unique/Primary Key)的字段插入重复值。 |
下面是一个除零异常示例:
declare
aaa int;
begin
aaa:= 10/0;
exception
when ZERO_DIVIDE then
raise notice 'exception: division_by_zero';
end;
/
NOTICE: exception: division_by_zero
15.4.用户自定义异常
您可以在任何PL/SQL块,函数、存储过程或者包中声明一个异常。
语法格式
exception_name EXCEPTION ;
用户自定义异常必须被显示触发。
用户自定义异常可以与一个错误码进行绑定,具体语法为:
PRAGMA EXCEPTION_INIT (exception, error_code) ;
其中 exception 是用户自定义的异常,error_code是大于 -1000000 且小于 0 的整数,error_code可以是系统预定义异常的错误码。
注意
EXCEPTION_INIT仅可为当前声明块中声明的自定义异常进行错误码绑定。
当为包声明中声明的自定义异常进行错误码绑定时,无法使用包名对异常名称进行修饰。即如下语法是错误的:
PRAGMA EXCEPTION_INIT (package.exception, error_code) ;
15.5.RAISE语句
RAISE语句可以显示的触发一个异常。在异常处理程序之外,RAISE语句必须指定异常名称。如果在异常处理程序内部,且省略了异常名称,那么该RAISE语句将重新引发当前正在处理的异常。
语法格式:
RAISE [ exception ];
其中 exception 可以是已定义的用户自定义异常,也可以是系统预定义异常。省略 exception的RAISE子句仅可在异常处理模块中使用。
RAISE 语句可以显示的触发用户自定义的异常。示例如下:
declare
aaa exception;
begin
raise aaa;
EXCEPTION
WHEN aaa THEN
raise notice 'has a exception';
WHEN OTHERS THEN
raise notice 'has a exception, info: %, %', sqlstate, SQLERRM;
end;
/
NOTICE: has a exception
系统预定义异常通常由系统运行时隐式触发,但也可以使用RAISE语句显式地触发它们。当一个预定义常拥有对应的异常处理程序时,无论是显式触发还是隐式触发,都会触发异常处理程序对相应的异常进行处理。
示例:参见除零异常示例。
15.6.RAISE_APPLICATION_ERROR
存储过程RAISE_APPLICATION_ERROR通常用来抛出一个用户自定义异常,并将错误码和错误信息传播给调用者。
要调用RAISE_APPLICATION_ERROR,请使用以下语法:
RAISE_APPLICATION_ERROR (error_code, message);
其中 error_code 是-20999 .. -20000之间的整数,message是长度为 2048 字节的字符串,大于该长度的字符会被自动截断。
使用RAISE_APPLICATION_ERROR抛出的用户定义的异常必须已使用PRAGMA EXCEPTION_INIT分配 error_code。
通过存储过程RAISE_APPLICATION_ERROR抛出的异常可以用OTHERS进行捕获处理,也可以通过绑定了相同 error_code的用户自定义异常进行捕获处理。
示例如下:
declare
aaa exception;
PRAGMA EXCEPTION_INIT (aaa, -20005);
begin
RAISE_APPLICATION_ERROR(-20005, ' bbbbb');
exception
when aaa then
raise notice 'has a exception aaa: %, %, %', sqlstate, sqlcode, sqlerrm;
when others then
raise notice 'others: %, %, %', sqlstate, sqlcode, sqlerrm;
end;
/
NOTICE: has a exception aaa: P0999, -20005, ERRCODE-20005: bbbbb
15.7.异常捕获和处理
异常捕获是异常处理程序的一部分,通常通过EXCEPTION子句对异常进行捕获操作。
通常情况下,一个语句引发异常,将导致当前语句退出执行,与该语句处于同一个事务内的语句也会被回滚。为了处理异常,PL/SQL块中可以通过EXCEPTION子句来捕获异常,进行相应处理,这时,处于同一个事务块中已经执行的的语句不会被回滚,但当前语句被回滚。
UXDB的PL/SQL中,当一条语句执行后,控制权将移交到下一条语句,但是当异常触发后,UXDB的PL/SQL将立即捕获、处理异常。
-
语法格式
[ DECLARE [ < VariableDeclaration > ] [ < CursorDeclaration > ] [ < UserDefinedExceptionDeclaration > ] ] BEGIN < Statements > EXCEPTION WHEN ExceptionName [ OR ExceptionName... ] THEN < HandlerStatements >; [ WHEN ExceptionName[ OR ExceptionName... ] THEN < HandlerStatements >; ... ] END; -
功能
捕获异常。
-
使用说明
-
ExceptionName,异常的名称,系统预先定义或用户自定义异常,直接使用即可,异常名称大小写均可,如 division_by_zero ,表示发生” 除零” 错误。异常名是与大小写无关的。
-
ExceptionName 可以使用关键字
OTHERS,用于处理在OTHERS之前没有显示指定处理的异常。 -
如果没有发生异常,这种形式的块只是简单地执行所有Statements ,然后转到
END之后的下一个语句。但是如果在Statements内发生了一个错误,则会放弃对Statements的进一步处理,然后转到EXCEPTION子句。系统会在异常条件列表中匹配当前触发的异常。如果匹配成功,则执行对应HandlerStatements ,执行完成 后转到
END之后的下一个语句。如果匹配失败,则该异常就会传播出去,就像没有EXCEPTION子句一样。异常可以被外层闭合块中的
EXCEPTION子句捕获,如果没有EXCEPTION则中止该程序的执行。 -
如果在选中的 HandlerStatements 内触发新的异常,那么它不能被当前这个
EXCEPTION子句捕获,而是被传播出去。由外层的EXCEPTION子句捕获它。 -
当一个异常被
EXCEPTION子句捕获时,PL/SQL 函数的局部变量会保持异常触发时的值,但是该块中所有对 数据库状态的改变都会被回滚。 -
进入和退出一个包含
EXCEPTION子句的块要比不包含EXCEPTION的块开销大的多。因此,尽量在必要的 时候使用EXCEPTION子句。
-